06-BestPracticesCloud
Best Practices Cloud Platforms#
This section is a collection of best practices on how you can arrange the tools together to a platform.
It's here especially to help you start your own project in the cloud on AWS, Azure and GCP.
Like the advanced skills section this section also follows my My Data Science Platform Blueprint. In the blueprint I divided the platform into sections: Connect, Buffer, Processing, Store and Visualize.
This order will help you learn how to connect the right tools together. Take your time and research the tools and learn how they work.
Right now the Azure section has a lot of links to platform examples. They are also useful for AWS and GCP, just try to change out the tools.
As always, I am going to add more stuff to this over time.
Have fun!
Contents#
AWS#
Connect#
- Elastic Beanstalk (very old)
- SES Simple Email Service
- API Gateway
Buffer#
- Kinesis
- Kinesis Data Firehose
- Managed Streaming for Kafka (MSK)
- MQ
- Simple Queue Service (SQS)
- Simple Notification Service (SNS)
Processing#
- EC2
- Athena
- EMR
- Elasticsearch
- Kinesis Data Analytics
- Glue
- Step Functions
- Fargate
- Lambda
- SageMaker
Store#
- Simple Storage Service (S3)
- Redshift
- Aurora
- RDS
- DynamoDB
- ElastiCache
- Neptune Graph DB
- Timestream
- DocumentDB (MongoDB compatible)
Visualize#
- Quicksight
Containerization#
- Elastic Container Service (ECS)
- Elastic Container Registry (ECR)
- Elastic Kubernetes Service (EKS)
Best Practices#
Deploying a Spring Boot Application on AWS Using AWS Elastic Beanstalk:
How to deploy a Docker Container on AWS:
https://aws.amazon.com/getting-started/hands-on/deploy-docker-containers/
AWS platform architecture for GenAI#
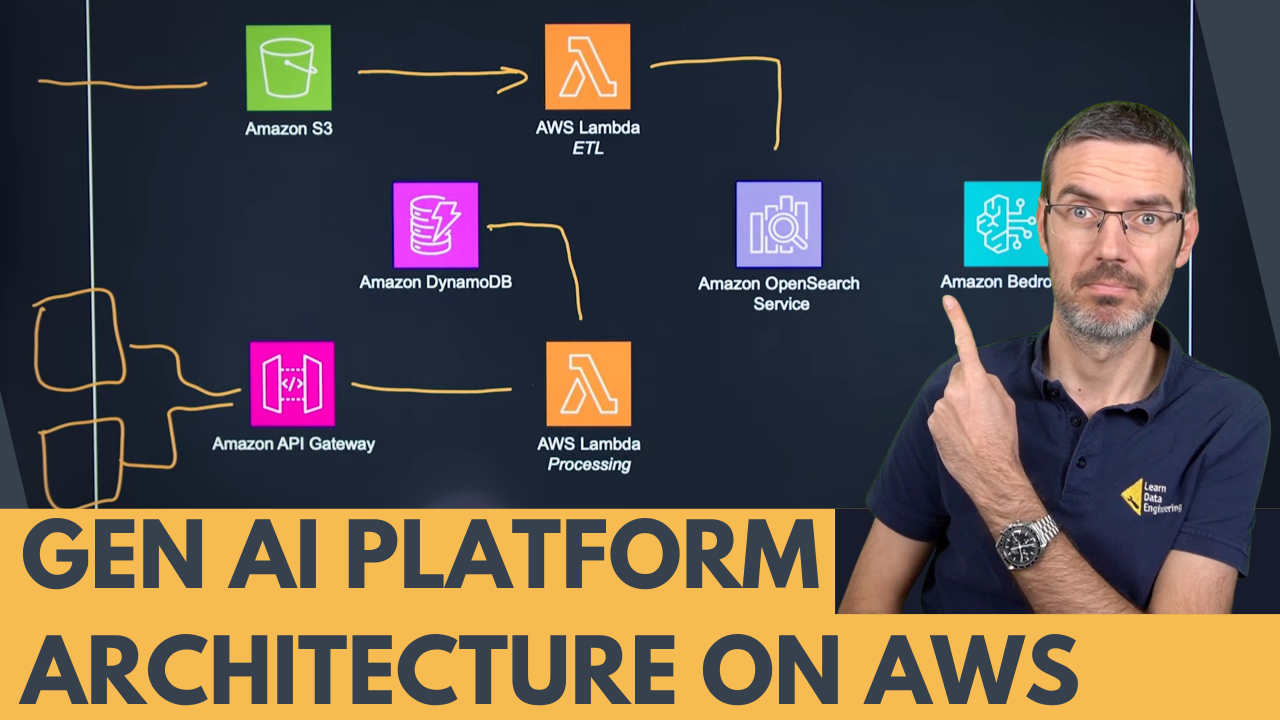 ▶
▶ I recorded a reaction video to an AWS platform architecture for GenAI called Tailwinds. Presented by John from Innovative Solutions and Josh from AWS, it has two main flows: indexing and consumer.
Data enters through S3 buckets or an API gateway, processed by AWS Lambda or Glue, and stored in a vector or graph database, then indexed in OpenSearch. Applications like chatbots use an API gateway to trigger Lambda functions for data retrieval and processing. This flexible serverless setup supports various data formats and uses tools like SAM and Terraform.
Amazon Bedrock helps customers choose and evaluate models. The architecture is flexible but requires effort to create the necessary Lambda functions. Check out the video and share your thoughts!
Generative AI enabled job search engine#

Hey everyone, I recorded a reaction video to an AWS platform architecture for a Gen AI job search engine. Presented by Andrea from AWS and Bill from Healthy Careers, this setup uses generative AI to enhance job searches for healthcare professionals.
The architecture uses Elastic Container Service (ECS) to handle user queries, processed by Claude II for prompt checks and geolocation. Cleaned prompts are vectorized using Amazon's Titan model, with user search history fetched from an SQL database. Search results are stored in Elasticsearch, updating every six hours. Finally, Claude II generates a response from the search results and sends it back to the user.
I found the use of Claude II for prompt sanitization and geolocation, and the integration of multiple AI models through AWS Bedrock, particularly interesting. This setup keeps data private and provides a flexible, efficient job search experience.
Check out the video and share your thoughts!
Voice transcription and analysis on AWS#
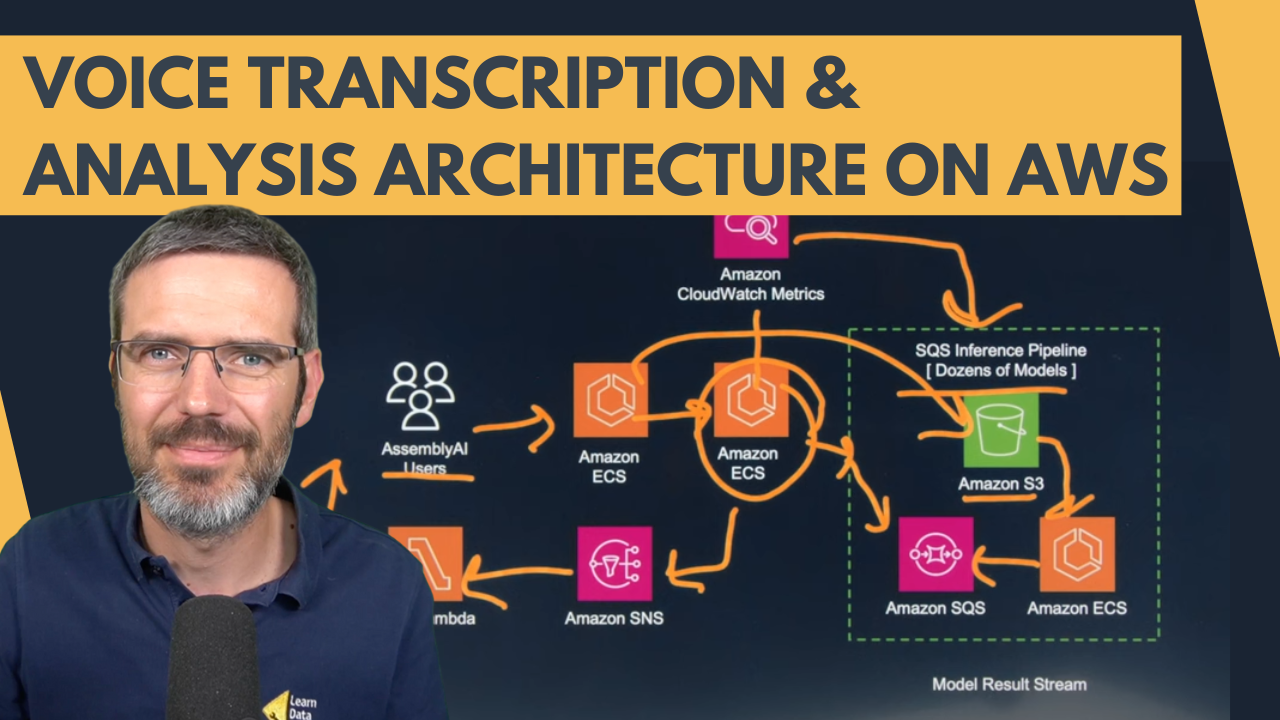
Hey everyone, I recorded a reaction video to an AWS architecture for voice transcription and analysis. Presented by Nuan from AWS and Ben from Assembly AI, this system is designed to handle large-scale audio data processing.
Users upload audio data via an API to an ECS container. The data is then managed by an orchestrator that decides which models to use and in what order. The orchestrator sends tasks to SQS, which triggers various ML models running on ECS. These models handle tasks like speech-to-text conversion, sentiment analysis, and speaker labeling. Results are stored in S3 and users are notified via SNS and a Lambda function when processing is complete.
I found the use of ECS for containerized applications and the flexibility of swapping models through ECR particularly interesting. This architecture ensures scalability and efficiency, making it ideal for handling millions of requests per day.
Check out the video and share your thoughts!
GeoSpatial Data Analysis#

Hey everyone, I recorded a reaction video to an AWS architecture for geospatial data analysis by TCS. Presented by David John and Suryakant from TCS, this platform is used in next-gen agriculture for tasks like crop health, yield, and soil moisture analysis.
The platform uses data from satellites, AWS open data, and field agents, processing it with Lambda, Sagemaker, and PostgreSQL. Data is stored and analyzed in S3 buckets and PostgreSQL, with results made accessible via EKS-deployed UIs on EC2 instances, buffered through CloudFront for efficiency.
Key aspects include:
- Lambda functions triggering Sagemaker jobs for machine learning.
- Sagemaker handling extensive processing tasks.
- PostgreSQL and S3 for storing processed data.
- CloudFront caching data to enhance user experience.
- I found the use of parallel Sagemaker jobs for scalability and the integration of open data for cost efficiency particularly interesting. This setup effectively meets the agricultural sector's data analysis needs.
Check out the video and share your thoughts!
Building a Self-Service Enterprise Data Engineering Platform#
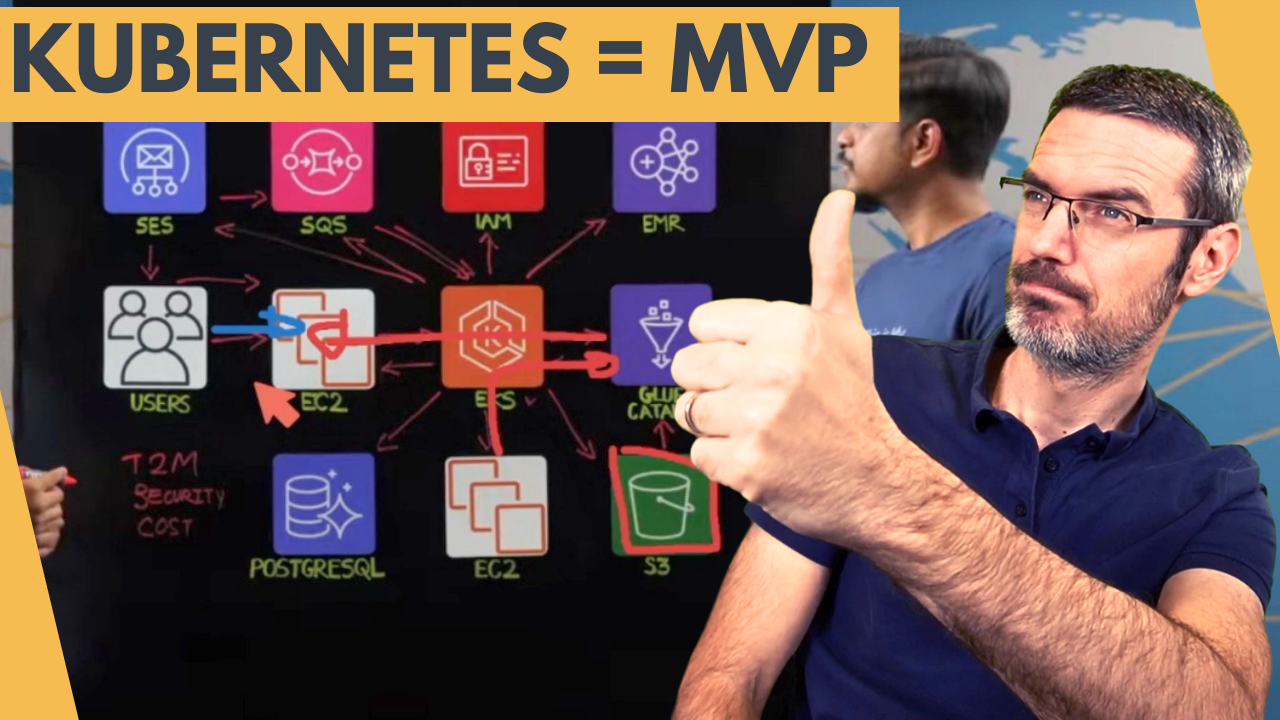
Hey everyone, I recorded a reaction video to an AWS architecture for a self-service enterprise data engineering platform by ZS Associates. Presented by David John and Laken from ZS Associates, this platform is designed to streamline data integration, infrastructure provisioning, and data access for life sciences companies.
Key components:
- Users and Interaction: Data engineers and analysts interact through a self-service web portal, selecting infrastructure types and providing project details. This portal makes REST requests to EKS, which creates records in PostgreSQL and triggers infrastructure provisioning via SQS.
- Infrastructure Provisioning: EKS processes SQS messages to provision infrastructure such as EMR clusters, databases in Glue Catalog, S3 buckets, and EC2 instances with containerized services like Airflow or NiFi. IAM roles are configured for access control.
- Data Governance and Security: All data sets are accessed through the Glue Catalog, with governance workflows requiring approval from data owners via SES notifications. EKS updates IAM roles and Ranger policies for fine-grained access control.
- Scalability and Efficiency: EKS hosts 100+ microservices supporting workflows and UI portals. The platform handles millions of API requests and hundreds of data access requests monthly, with auto-scaling capabilities to manage costs.
This architecture effectively reduces time to market, enhances security at scale, and optimizes costs by automating data access and infrastructure provisioning. It also ensures data governance and security through controlled access and approval processes.
Check out the video and share your thoughts!
Customer Support Platform#

Hey everyone, I recorded a reaction video to an AWS architecture for a personalized customer support platform by Traeger. Presented by David John and Lizzy from Traeger, this system enhances customer support by leveraging data from Shopify, EventBridge, Kinesis Data Firehose, S3, Lambda, DynamoDB, and Amazon Connect.
Key components:
- Order Processing: Customer order data from Shopify flows into EventBridge, then to Kinesis Data Firehose, which writes it to S3. An event trigger in S3 invokes a Lambda function that stores specific order metadata in DynamoDB.
- Personalized Customer Support: When a customer calls, Amazon Connect uses Pinpoint to determine the call's origin, personalizing the language options. Connect triggers a Lambda function to query DynamoDB for customer metadata based on the phone number. This data is used to inform the customer support agent.
- Reason for Contact: Amazon Lex bot asks the customer the reason for their call, and this information, along with customer metadata, routes the call to a specialized support queue.
I found the use of DynamoDB for storing customer metadata and the integration with Amazon Connect and Lex for personalized support particularly interesting. The architecture is scalable and ensures a personalized experience for customers.
Check out the video and share your thoughts!
League of Legends Data Platform on AWS#
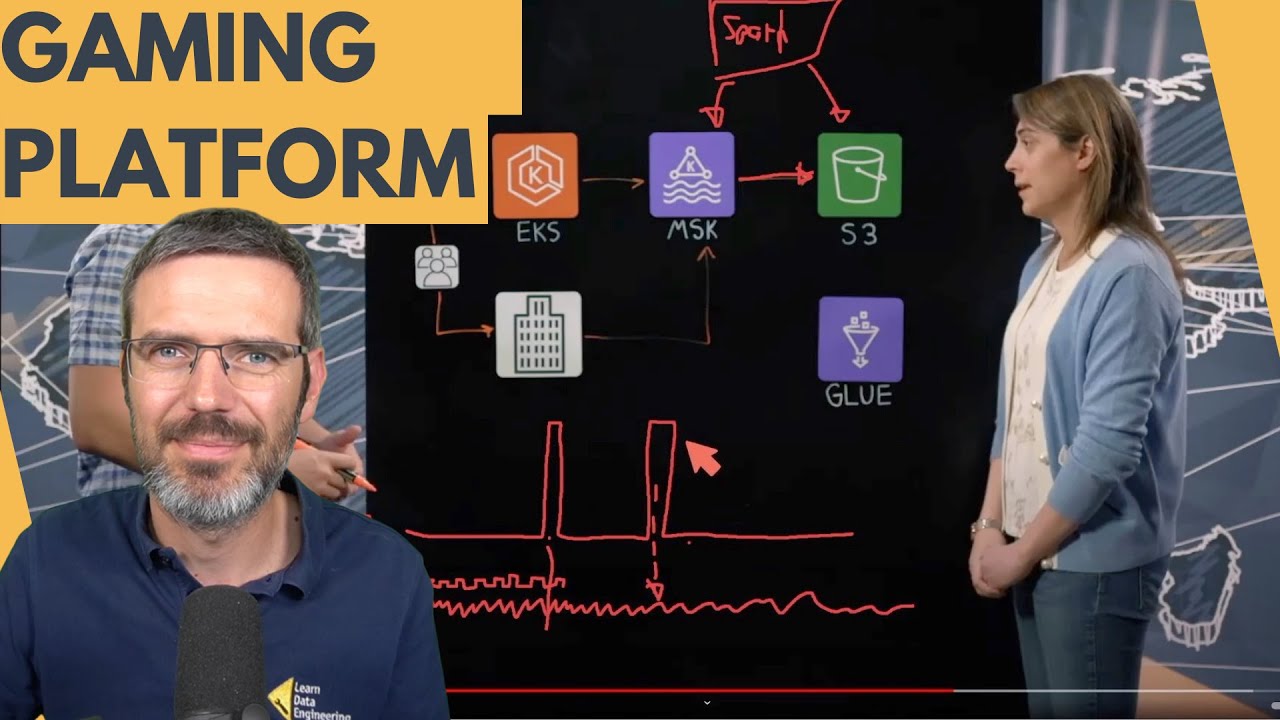
Hey everyone, I recorded a reaction video to an AWS architecture for the data platform that powers League of Legends by Riot Games. Presented by David John and the team at Riot Games, this system handles massive amounts of data generated by millions of players worldwide.
Key components:
- Player Interaction: Players connect to game servers globally. The game client communicates with an API running in EKS. This setup ensures low latency and optimal performance.
- Data Ingestion: The game client and server send data about player interactions to EKS, which flows into MSK (Managed Streaming for Kafka). Local Kafka clusters buffer the data before it’s replicated to regional MSK clusters using MirrorMaker.
- Data Processing: Spark Streaming jobs process the data from MSK and store it in Delta Lake on S3. This setup ensures efficient data handling and reduces latency in data availability.
- Data Storage and Access: Glue serves as the data catalog, managing metadata and permissions. Data consumers, including analysts, designers, engineers, and executives, access this data through Databricks, leveraging Glue for structured queries.
I found the use of MSK and Spark for scalable data ingestion and processing particularly interesting. This architecture supports real-time analytics, allowing Riot Games to quickly assess the impact of new patches and gameplay changes.
Check out the video and share your thoughts!
Platform Connecting 70 Million Cars#
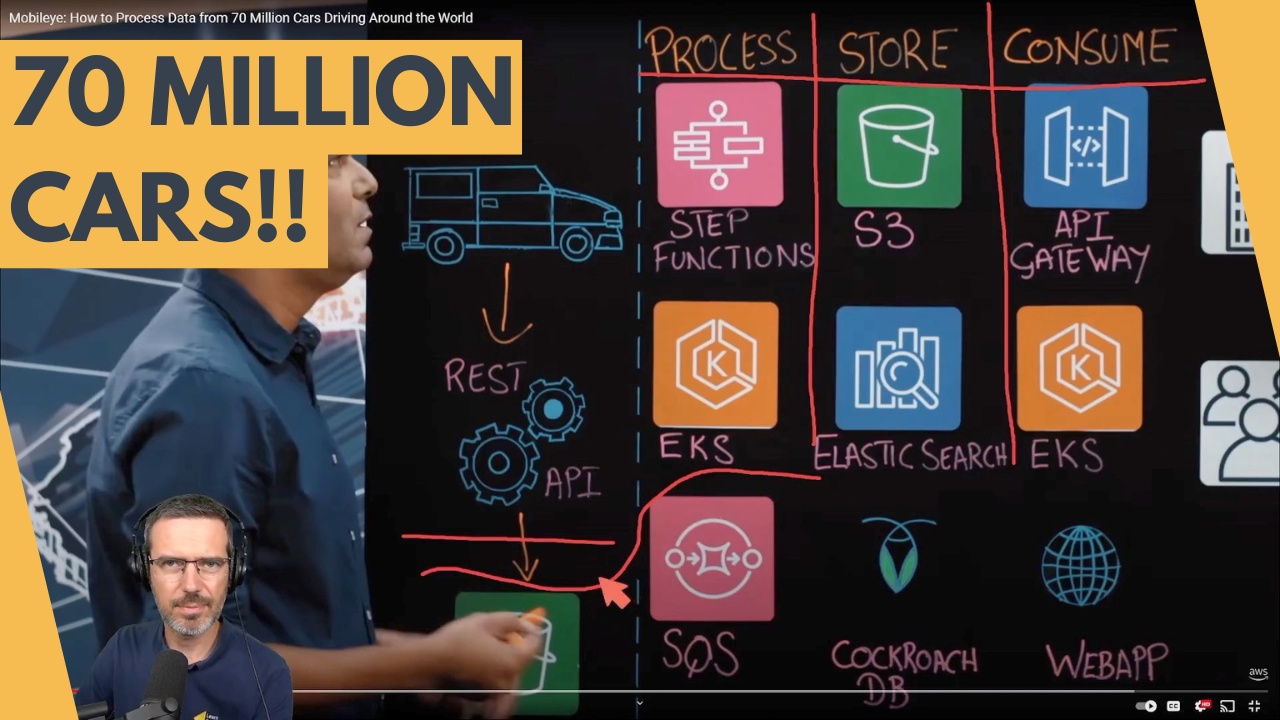
Hey everyone, I recorded a reaction video to an AWS architecture for a connected car platform by Mobileye. Presented by David John and the team at Mobileye, this system connects 70 million cars, collecting and processing data to offer digital services and fleet analysis.
Key components:
- Data Collection: Cars collect anonymized data using sensors and visual inspections, sending it to a REST API and storing it in S3.
- Data Processing: The data is pulled from S3 into SQS and processed by EKS workers, which scale according to the queue size. Processed data is stored back in S3 and further analyzed using step functions and Lambda for tasks like extracting construction zones and clustering observations.
- Data Storage: Processed data is stored in S3, Elasticsearch, and CockroachDB. Elasticsearch handles document-based data with self-indexing, while CockroachDB supports frequent updates.
- Data Consumption: EKS hosts a secured REST API and web application, allowing customers like city planners to access insights on pedestrian and bicycle traffic.
Future plans include enabling cloud image processing on EKS with GPU instances and focusing on cost reduction as data flow increases.
I found the use of EKS for scalable data processing and the combination of Elasticsearch and CockroachDB for different data needs particularly interesting. This architecture efficiently handles large-scale data from millions of connected cars.
Check out the video and share your thoughts!
55TB A Day: Nielsen AWS Data Architecture#

Hey everyone, I recorded a reaction video to an AWS architecture for Nielsen Marketing Cloud, which processes 55TB of data daily. Presented by David John, this system handles marketing segmentation data for campaigns.
Key components:
- Data Ingestion: Marketing data comes in files, written to S3. Spark on EMR processes and transforms the data, writing the output to another S3 bucket.
- Data Processing: Lambda functions handle the final formatting and upload the data to over 100 ad networks. Metadata about file processing is managed in a PostgreSQL RDS database.
- Metadata Management: A work manager Lambda reads metadata from RDS, triggers processing jobs in EMR, and updates the metadata post-processing.
- Scaling and Rate Limiting: The serverless architecture allows automatic scaling. However, rate limiting is implemented to prevent overloading ad networks, ensuring they handle data bursts smoothly.
Challenges and Solutions:
- Scale: The system handles 250 billion events per day, scaling up and down automatically to manage peak loads.
- Rate Limiting: To avoid overwhelming ad networks, a rate-limiting mechanism was introduced, managing data flow based on network capacity.
- Back Pressure Management: SQS is used to buffer Lambda responses, preventing direct overload on the PostgreSQL database.
I found the use of SQS for metadata management and the serverless architecture for handling massive data loads particularly interesting. This setup ensures efficient data processing and smooth delivery to ad networks.
Check out the video and share your thoughts!
Orange Theory Fitness#
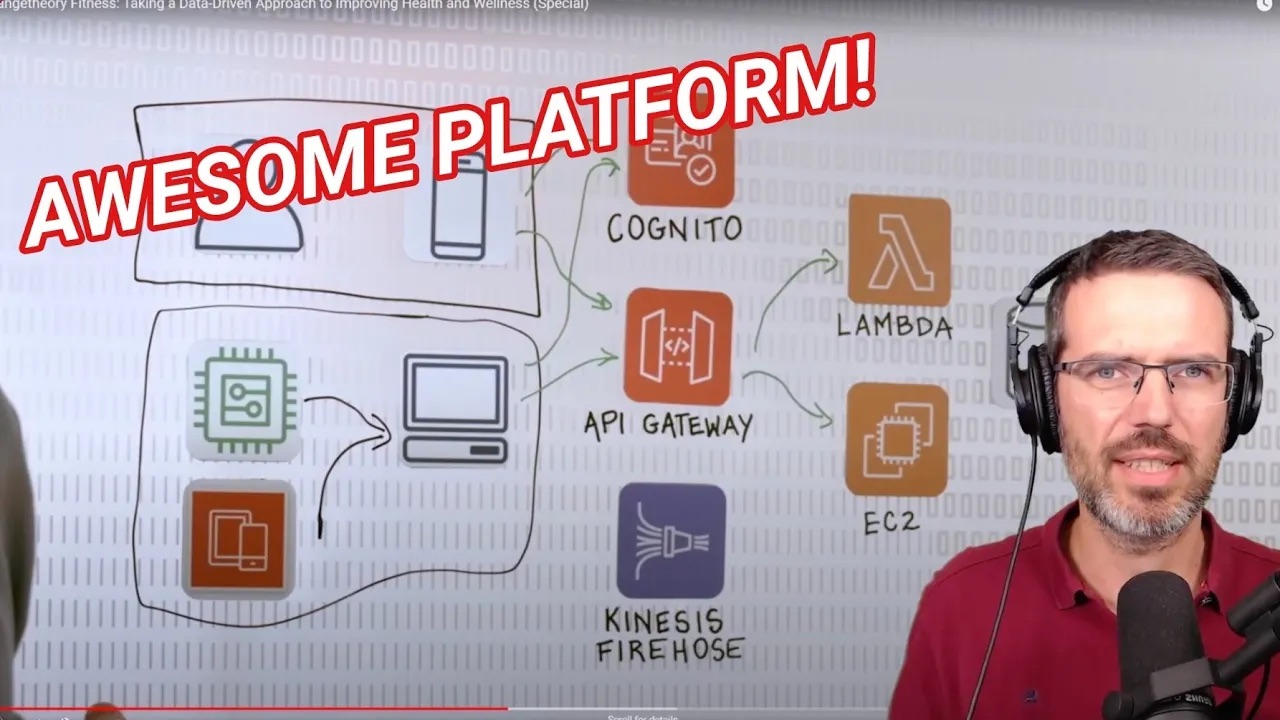
Hey, everybody! Today, I'm reacting to the AWS data infrastructure at Orange Theory Fitness, where they collect data from wristbands and training machines. Let's dive in and see how they manage it all.
Key Components#
- Local Server: Aggregates data from in-studio equipment and mobile apps, ensuring resiliency if the cloud connection is lost.
- API Gateway and Cognito: Handle authentication and route data to the cloud.
- Lambda Functions: Process data.
- Aurora RDS (MySQL): Stores structured data like member profiles, class bookings, and studio information.
- DynamoDB: Stores performance metrics and workout statistics for quick access.
- S3: Serves as a data lake, storing telemetry data.
- Kinesis Firehose: Streams telemetry data to S3.
Challenges & Solutions#
Resiliency
- Challenge: Ensure operations continue if cloud connection is lost.
- Solution: Local server aggregates data and syncs with the cloud once the connection is restored.
Data Integration
- Challenge: Integrate data from various sources.
- Solution: Use API Gateway and Cognito for unified authentication and data routing.
Data Processing
- Challenge: Efficiently process and store different types of data.
- Solution: Use Lambda for processing, Aurora RDS for structured data, DynamoDB for quick access to performance metrics, and Kinesis Firehose with S3 for streaming and storing large volumes of telemetry data.
This architecture leverages AWS tools for scalability, flexibility, and resilience, making it an excellent example of a well-thought-out data infrastructure for a fitness application.
Let me know your thoughts in the comments. What do you think of this architecture? Would you have done anything differently? If you have any questions, feel free to ask. And if you're interested in learning more about data engineering, check out my academy at learndataengineering.com. See you in the next video!
More Details#
AWS Whitepapers:
https://d1.awsstatic.com/whitepapers/aws-overview.pdf
Azure#
Connect#
- Event Hub
- IoT Hub
Buffer#
- Data Factory
- Event Hub
- RedisCache (also Store)
Processing#
- Stream Analytics Service
- Azure Databricks
- Machine Learning
- Azure Functions
- Azure HDInsight (Hadoop PaaS)
Store#
- Blob
- CosmosDB
- MariaDB
- MySQL
- PostgreSQL
- SQL
- Azure Data lake
- Azure Storage (SQL Table?)
- Azure Synapse Analytics
Visualize#
- PowerBI
Containerization#
- Virtual Machines
- Virtual Machine Scale Sets
- Azure Container Service (AKS)
- Container Instances
- Azure Kubernetes Service
Best Practices#
Advanced Analytics Architecture:
Anomaly Detection in Real-time Data Streams:
Modern Data Warehouse Architecture:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/modern-data-warehouse
CI/CD for Containers:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/cicd-for-containers
Real Time Analytics on Big Data Architecture:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/real-time-analytics
Anomaly Detection in Real-time Data Streams:
IoT Architecture – Azure IoT Subsystems:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/azure-iot-subsystems
Tier Applications & Data for Analytics:
Extract, transform, and load (ETL) using HDInsight:
IoT using Cosmos DB:
https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/iot-using-cosmos-db
Streaming using HDInsight:
GCP#
Connect#
- Cloud IoT Core
- App Engine
- Cloud Dataflow
Buffer#
- Pub/Sub
Processing#
- Compute Engine
- Cloud Functions
- Specialized tools:
- Cloud Dataflow
- Cloud Dataproc
- Cloud Datalab
- Cloud Dataprep
- Cloud Composer
- App Engine
Store#
- Cloud Storage
- Cloud SQL
- Cloud Spanner
- Cloud Datastore
- Cloud BigTable
- Cloud Storage
- Cloud Memorystore
- BigQuery
Visualize#
Containerization#
- Kubernetes Engine
- Container Security
Best Practices#
Thanks to Ismail Holoubi for the following GCP links
Best practices for migrating virtual machines to Compute Engine:
https://cloud.google.com/solutions/best-practices-migrating-vm-to-compute-engine
Best practices for Cloud Storage:
https://cloud.google.com/storage/docs/best-practices
Moving a publishing workflow to BigQuery for new data insights:
Architecture: Optimizing large-scale ingestion of analytics events and logs:
https://cloud.google.com/solutions/architecture/optimized-large-scale-analytics-ingestion
Choosing the right architecture for global data distribution:
https://cloud.google.com/solutions/architecture/global-data-distribution
Best Practices for Operating Containers:
https://cloud.google.com/solutions/best-practices-for-operating-containers
Automating IoT Machine Learning: Bridging Cloud and Device Benefits with AI Platform:
https://cloud.google.com/solutions/automating-iot-machine-learning