01-Introduction
Introduction#
Contents#
- What is this Cookbook
- Data Engineers
- My Data Science Platform Blueprint
- Who Companies Need
- How to Learn Data Engineering
- Data Engineers Skills Matrix
- How to Become a Senior Data Engineer
What is this Cookbook#
I get asked a lot: "What do you actually need to learn to become an awesome data engineer?"
Well, look no further. You'll find it here!
If you are looking for AI algorithms and such data scientist things, this book is not for you.
How to use this Cookbook: This book is intended to be a starting point for you. It is not a training! I want to help you to identify the topics to look into to become an awesome data engineer in the process.
It hinges on my Data Science Platform Blueprint. Check it out below. Once you understand it, you can find in the book tools that fit into each key area of a Data Science platform (Connect, Buffer, Processing Framework, Store, Visualize).
Select a few tools you are interested in, then research and work with them.
Don't learn everything in this book! Focus.
What types of content are in this book? You are going to find five types of content in this book: Articles I wrote, links to my podcast episodes (video & audio), more than 200 links to helpful websites I like, data engineering interview questions and case studies.
This book is a work in progress! As you can see, this book is not finished. I'm constantly adding new stuff and doing videos for the topics. But, obviously, because I do this as a hobby, my time is limited. You can help make this book even better.
Help make this book awesome! If you have some cool links or topics for the cookbook, please become a contributor on GitHub: https://github.com/andkret/Cookbook. Fork the repo, add them, and create a pull request. Or join the discussion by opening Issues. Tell me your thoughts, what you value, what you think should be included, or correct me where I am wrong. You can also write me an email any time to plumbersofdatascience\@gmail.com anytime.
This Cookbook is and will always be free!
If You Like This Book & Need More Help:#
Check out my Data Engineering Academy at LearnDataEngineering.com
Visit learndataengineering.com: Click Here
- Huge Step by step Data Engineering Academy with over 30 courses
- Unlimited access incl. future courses during subsciption
- Access to all courses and example projects in the Academy
- Associate Data Engineer Certification
- Data Engineering on AWS E-Commerce example project
- Microsoft Azure example project
- Document Streaming example project with Docker, FastAPI, Apache Kafka, Apache Spark,
- MongoDB and Streamlit
- Time Series example project with InfluxDB and Grafana
- Lifetime access to the private Discord Workspace
- Course certificates
- Currently over 54 hours of videos
Support This Book For Free!#
- Amazon: Click Here buy whatever you like from Amazon using this link* (Also check out my complete podcast gear and books)
How To Contribute#
If you have some cool links or topics for the cookbook, please become a contributor.
Simply pull the repo, add your ideas and create a pull request. You can also open an issue and put your thoughts there.
Please use the "Issues" function for comments.
Data Engineers#
Data Engineers are the link between the management's data strategy and the data scientists or analysts that need to work with data.
What they do is build the platforms that enable data scientists to do their magic.
These platforms are usually used in five different ways:
Data ingestion and storage of large amounts of data.
Algorithm creation by data scientists.
Automation of the data scientist's machine learning models and algorithms for production use.
Data visualization for employees and customers.
Most of the time these guys start as traditional solution architects for systems that involve SQL databases, web servers, SAP installations and other "standard" systems.
But, to create big data platforms, the engineer needs to be an expert in specifying, setting up, and maintaining big data technologies like: Hadoop, Spark, HBase, Cassandra, MongoDB, Kafka, Redis, and more.
What they also need is experience on how to deploy systems on cloud infrastructure like at Amazon or Google, or on-premise hardware.
| Podcast Episode: #048 From Wannabe Data Scientist To Engineer My Journey
|------------------|
|In this episode Kate Strachnyi interviews me for her humans of data science podcast. We talk about how I found out that I am more into the engineering part of data science.
| Watch on YouTube \ Listen on Anchor|
My Data Science Platform Blueprint#
I have created a simple and modular big data platform blueprint. It is based on what I have seen in the field and read in tech blogs all over the internet.
Why do I believe it will be super useful to you? Because, unlike other blueprints, it is not focused on technology.
Following my blueprint will allow you to create the big data platform that fits exactly your needs. Building the perfect platform will allow data scientists to discover new insights. It will enable you to perfectly handle big data and allow you to make data-driven decisions.
The blueprint is focused on the five key areas: Connect, Buffer, Processing Frameworks, Store, and Visualize.
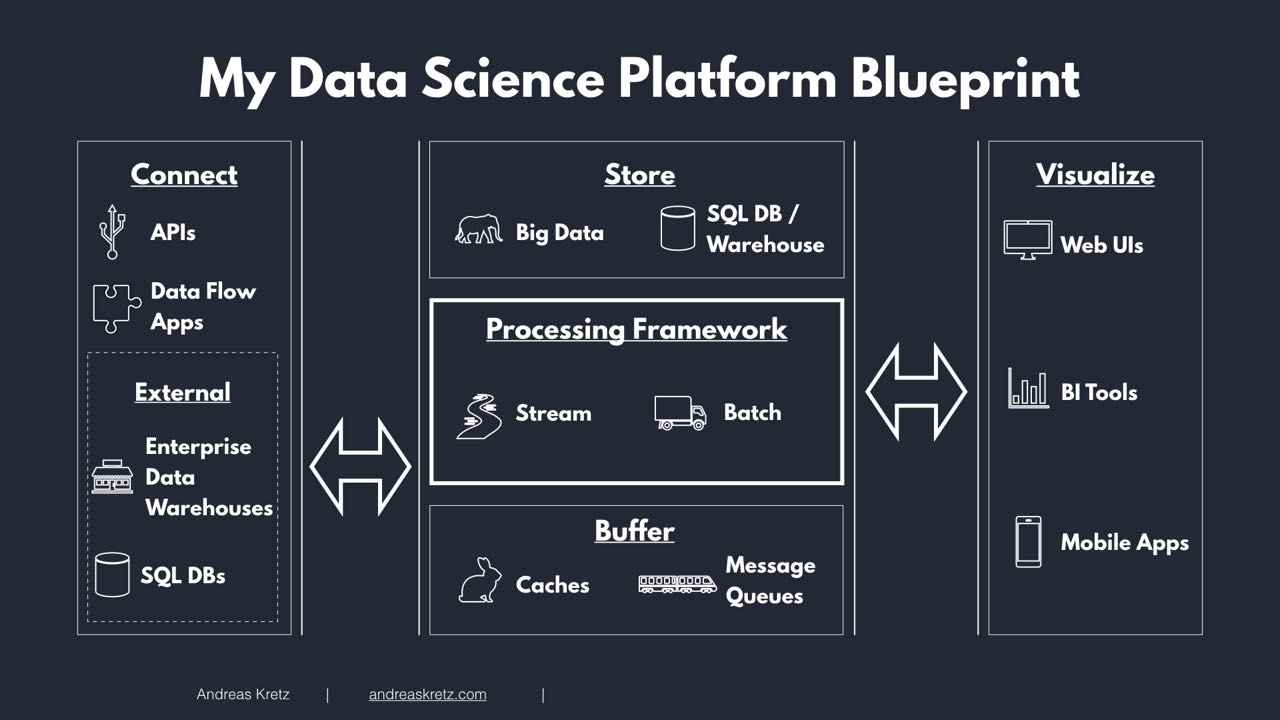
Having the platform split like this turns it into a modular platform with loosely coupled interfaces.
Why is it so important to have a modular platform?
If you have a platform that is not modular, you end up with something that is fixed or hard to modify. This means you can not adjust the platform to changing requirements of the company.
Because of modularity, it is possible to specifically select tools for your use case. It also allows you to replace every component, if you need it.
Now, lets talk more about each key area.
Connect#
Ingestion is all about getting the data in from the source and making it available to later stages. Sources can be everything from tweets to server logs, to IoT sensor data (e.g. from cars).
Sources send data to your API Services. The API is going to push the data into temporary storage.
The temporary storage allows other stages simple and fast access to incoming data.
A great solution is to use messaging queue systems like Apache Kafka, RabbitMQ or AWS Kinesis. Sometimes people also use caches for specialised applications like Redis.
A good practice is that the temporary storage follows the publish-subscribe pattern. This way APIs can publish messages and Analytics can quickly consume them.
Buffer#
In the buffer phase you have pub/sub systems like Apache Kafka, Redis, or other Cloud tools like Google pub/sub or AWS Kinesis.
These systems are more or less message Queues. You put something in on one side and take it out on the other.
The idea behind buffers is to have an intermediate system for the incoming data.
How this works is, for instance, you're getting data in from from an API. The API is publishing into the message queue. Data is buffered there until it is picked up by the processing.
If you don't have a buffer, you can run into problems when writing directly into a store or you're processing the data directly. You can always have peaks of incoming data that stall the systems.
Like, it's lunch break and people are working with your app way more than usual. There's more data coming in very very fast, faster than the analytics of the storage can handle.
In this case, you would run into problems, because the whole system would stall. It would therefore take long to process the data, and your customers would be annoyed.
With a buffer, you buffer the incoming data. Processes for storage and analytics can take out only as much data as they can process. You are no longer in danger of overpowering systems.
Buffers are also really good for building pipelines.
You take data out of Kafka, pre-process it, and put it back into Kafka. Then, with another analytics process, you take the processed data back out and put it into a store.
Ta-da! A pipeline.
Processing Framework#
The analyse stage is where the actual analytics is done in the form of stream and batch processing.
Streaming data is taken from ingest and fed into analytics. Streaming analyses the "live" data, thus generating fast results.
As the central and most important stage, analytics also has access to the big data storage. Because of that connection, analytics can take a big chunk of data and analyse it.
This type of analysis is called batch processing. It will deliver you answers for the big questions.
For a short video about batch and stream processing and their use cases, click on the link below:
Adding Batch to a Streaming Pipeline
The analytics process, batch or streaming, is not a one-way process. Analytics can also write data back to the big data storage.
Oftentimes, writing data back to the storage makes sense. It allows you to combine previous analytics outputs with the raw data.
Analytics give insights when you combine raw data. This combination will often allow you to create even more useful insights.
A wide variety of analytics tools are available. Ranging from MapReduce or AWS Elastic MapReduce to Apache Spark and AWS lambda.
Store#
This is the typical big-data storage where you just store everything. It enables you to analyse the big picture.
Most of the data might seem useless for now, but it is of utmost importance to keep it. Throwing data away is a big no-no.
Why not throw something away when it is useless?
Although it seems useless for now, data scientists can work with the data. They might find new ways to analyse the data and generate valuable insights from it.
What kind of systems can be used to store big data?
Systems like Hadoop HDFS, Hbase, Amazon S3 or DynamoDB are a perfect fit to store big data.
Check out my podcast how to decide between SQL and NoSQL: https://anchor.fm/andreaskayy/embed/episodes/NoSQL-Vs-SQL-How-To-Choose-e12f1o
Visualize#
Displaying data is as important as ingesting, storing, and analysing it. Visualizations enable business users to make data-driven decisions.
This is why it is important to have a good visual presentation of the data. Sometimes you have a lot of different use cases or projects using the platform.
It might not be possible to build the perfect UI that fits everyone's needs. What you should do in this case is enable others to build the perfect UI themselves.
How to do that? By creating APIs to access the data and making them available to developers.
Either way, UI or API, the trick is to give the display stage direct access to the data in the big-data cluster. This kind of access will allow the developers to use analytics results as well as raw data to build the perfect application.
Who Companies Need#
For a company, it is important to have well-trained data engineers.
That's why companies are looking for people with experience of tools in every part of the above platform blueprint. One common theme I see is cloud platform experience on AWS, Azure or GCP.
How to Learn Data Engineering#
Interview with Andreas on the Super Data Science Podcast#
Summary#
This interview with Andreas on Jon Krohn's Super Data Science podcast delves into the intricacies of data engineering, highlighting its critical role in the broader data science ecosystem. Andreas, calling from Northern Bavaria, Germany, shares his journey from a data analyst to becoming a renowned data engineering educator through his Learn Data Engineering Academy. The conversation touches upon the foundational importance of data engineering in ensuring data quality, scalability, and accessibility for data scientists and analysts.
Andreas emphasizes that the best data engineers often have a background in the companies domain/niche, which equips them with a deep understanding of the end user's needs. The discussion also explores the essential tools and skills required in the field, such as relational databases, APIs, ETL tools, data streaming with Kafka, and the significance of learning platforms like AWS, Azure, and GCP. Andreas highlights the evolving landscape of data engineering, with a nod towards the emergence of roles like analytics engineers and the increasing importance of automation and advanced data processing tools like Snowflake, Databricks, and DBT.
The interview is not just a technical deep dive but also a personal journey of discovery and passion for data engineering, underscoring the perpetual learning and adaptation required in the fast-evolving field of data science.
| Watch or listen to this interview -> 657: How to Learn Data Engineering — with Andreas Kretz |------------------| | Was super fun talking with Jon about Data Engineering on the podcast. Think this will be very helpful for you :) | Watch on YouTube / Listen to the Podcast|
Q&A Highlights#
Q: What is data engineering, and why is it important? A: Data engineering is the foundation of the data science process, focusing on collecting, cleaning, and managing data to make it accessible and usable for data scientists and analysts. It's crucial for automating data processes, ensuring data quality, and enabling scalable data analysis and machine learning models.
Q: How does one transition from data analysis to data engineering? A: The transition involves gaining a deep understanding of data pipelines, learning to work with various data processing and management tools, and developing skills in programming languages and technologies relevant to data engineering, such as SQL, Python, and cloud platforms like AWS or Azure.
Q: What are the key skills and tools for a data engineer? A: Essential skills include proficiency in SQL, experience with ETL tools, knowledge of programming languages like Python, and familiarity with cloud services and data processing frameworks like Apache Spark. Tools like Kafka for data streaming and platforms like Snowflake and Databricks are also becoming increasingly important.
Q: Can you elaborate on the emerging role of analytics engineers? A: Analytics engineers focus on bridging the gap between raw data management and data analysis, working closely with data warehouses and using tools like dbt to prepare and model data for easy analysis. This role is pivotal in making data more accessible and actionable for decision-making processes.
Q: What advice would you give to someone aspiring to become a data engineer? A: Start by mastering the basics of SQL and Python, then explore and gain experience with various data engineering tools and technologies. It's also important to understand the data science lifecycle and how data engineering fits within it. Continuous learning and staying updated with industry trends are key to success in this field.
Q: How does a data engineer's role evolve with experience? A: A data engineer's journey typically starts with focusing on specific tasks or segments of data pipelines, using a limited set of tools. As they gain experience, they broaden their skill set, manage entire data pipelines, and take on more complex projects. Senior data engineers often lead teams, design data architectures, and collaborate closely with data scientists and business stakeholders to drive data-driven decisions.
Q: What distinguishes data engineering from machine learning engineering? A: While both fields overlap, especially in the use of data, data engineering focuses on the infrastructure and processes for handling data, ensuring its quality and accessibility. Machine learning engineering, on the other hand, centers on deploying and maintaining machine learning models in production environments. A strong data engineering foundation is essential for effective machine learning engineering.
Q: Why might a data analyst transition to data engineering? A: Data analysts may transition to data engineering to work on more technical aspects of data handling, such as building and maintaining data pipelines, automating data processes, and ensuring data scalability. This transition allows them to have a more significant impact on the data lifecycle and contribute to more strategic data initiatives within an organization.
Q: Can you share a challenging project you worked on as a data engineer? A: One challenging project involved creating a scalable data pipeline for real-time processing of machine-generated data. The complexity lay in handling vast volumes of data, ensuring its quality, and integrating various data sources while maintaining high performance. This project highlighted the importance of selecting the right tools and technologies, such as Kafka for data streaming and Apache Spark for data processing, to meet the project's demands.
Q: How does the cloud influence data engineering? A: Cloud platforms like AWS, Azure, and GCP have transformed data engineering by providing scalable, flexible, and cost-effective solutions for data storage, processing, and analysis. They offer a wide range of services and tools that data engineers can leverage to build robust data pipelines and infrastructure, facilitating easier access to advanced data processing capabilities and enabling more innovative data solutions.
Q: What future trends do you see in data engineering? A: Future trends in data engineering include the increasing adoption of cloud-native services, the rise of real-time data processing and analytics, greater emphasis on data governance and security, and the continued growth of machine learning and AI-driven data processes. Additionally, tools and platforms that simplify data engineering tasks and enable more accessible data integration and analysis will become more prevalent, democratizing data across organizations.
Q: How does the background of a data analyst contribute to their success as a data engineer? A: Data analysts have a unique advantage when transitioning to data engineering due to their understanding of data's end-use. Their experience in analyzing data gives them insights into what makes data valuable and usable, enabling them to design more effective and user-centric data pipelines and storage solutions.
Q: What role does automation play in data engineering? A: Automation is crucial in data engineering for scaling data processes, reducing manual errors, and ensuring consistency in data handling. Automated data pipelines allow for real-time data processing and integration, making data more readily available for analysis and decision-making.
Q: Can you discuss the significance of cloud platforms in data engineering? A: Cloud platforms like AWS, Azure, and GCP offer scalable, flexible, and cost-effective solutions for data storage, processing, and analysis. They provide data engineers with a suite of tools and services to build robust data pipelines, implement machine learning models, and manage large volumes of data efficiently.
Q: How does data engineering support data science and machine learning projects? A: Data engineering lays the groundwork for data science and machine learning by preparing and managing the data infrastructure. It ensures that high-quality, relevant data is available for model training and analysis, thereby enabling more accurate predictions and insights.
Q: What emerging technologies or trends should data engineers be aware of? A: Data engineers should keep an eye on the rise of machine learning operations (MLOps) for integrating machine learning models into production, the growing importance of real-time data processing and analytics, and the adoption of serverless computing for more efficient resource management. Additionally, technologies like containerization (e.g., Docker) and orchestration (e.g., Kubernetes) are becoming critical for deploying and managing scalable data applications.
Q: What challenges do data engineers face, and how can they be addressed? A: Data engineers often grapple with data quality issues, integrating disparate data sources, and scaling data infrastructure to meet growing data volumes. Addressing these challenges requires a solid understanding of data architecture principles, continuous monitoring and testing of data pipelines, and adopting best practices for data governance and management.
Q: How important is collaboration between data engineers and other data professionals? A: Collaboration is key in the data ecosystem. Data engineers need to work closely with data scientists, analysts, and business stakeholders to ensure that data pipelines are aligned with business needs and analytical goals. Effective communication and a shared understanding of data objectives are vital for the success of data-driven projects.
Building Blocks to Learn Data Engineering#
The following Roadmaps all hinge on the courses in my Data Engineering Academy. They are designed to help students who come from many different professions and enable to build a customized curriculum.
Here are all the courses currently available February 2024:
Colors: Blue (The Basics), Green (Platform & Pipeline Fundamentals), Orange (Fundamental Tools), Red (Example Projects)
Roadmap for Beginners#
Start this roadmap at my Academy: Start Today
11-Week Data Engineering Roadmap for Beginners & Graduates#
Master the Fundamentals and Build Your First Data Pipelines#
Starting in Data Engineering#
Starting in data engineering can feel overwhelming, especially if you’re coming from a non-technical background or have only limited experience with coding and databases.
This 11-week roadmap, with a time commitment of 5–10 hours per week, is designed to help you build strong foundations in data engineering, step by step, before moving into cloud platforms and more advanced pipelines. You’ll learn essential concepts, hands-on coding, data modeling, and cloud ETL development—everything you need to kickstart your career as a data engineer.
Why This Roadmap is for You#
- You’re just starting in data engineering and need a clear learning path
- You want to build a strong foundation in data platforms, SQL, and Python
- You need hands-on experience with data modeling, cloud ETL, and automation
- You want to work on real-world projects that prepare you for a data engineering job
By the end of this roadmap, you’ll have the skills, tools, and project experience to confidently apply for entry-level data engineering roles and start your career in the field.
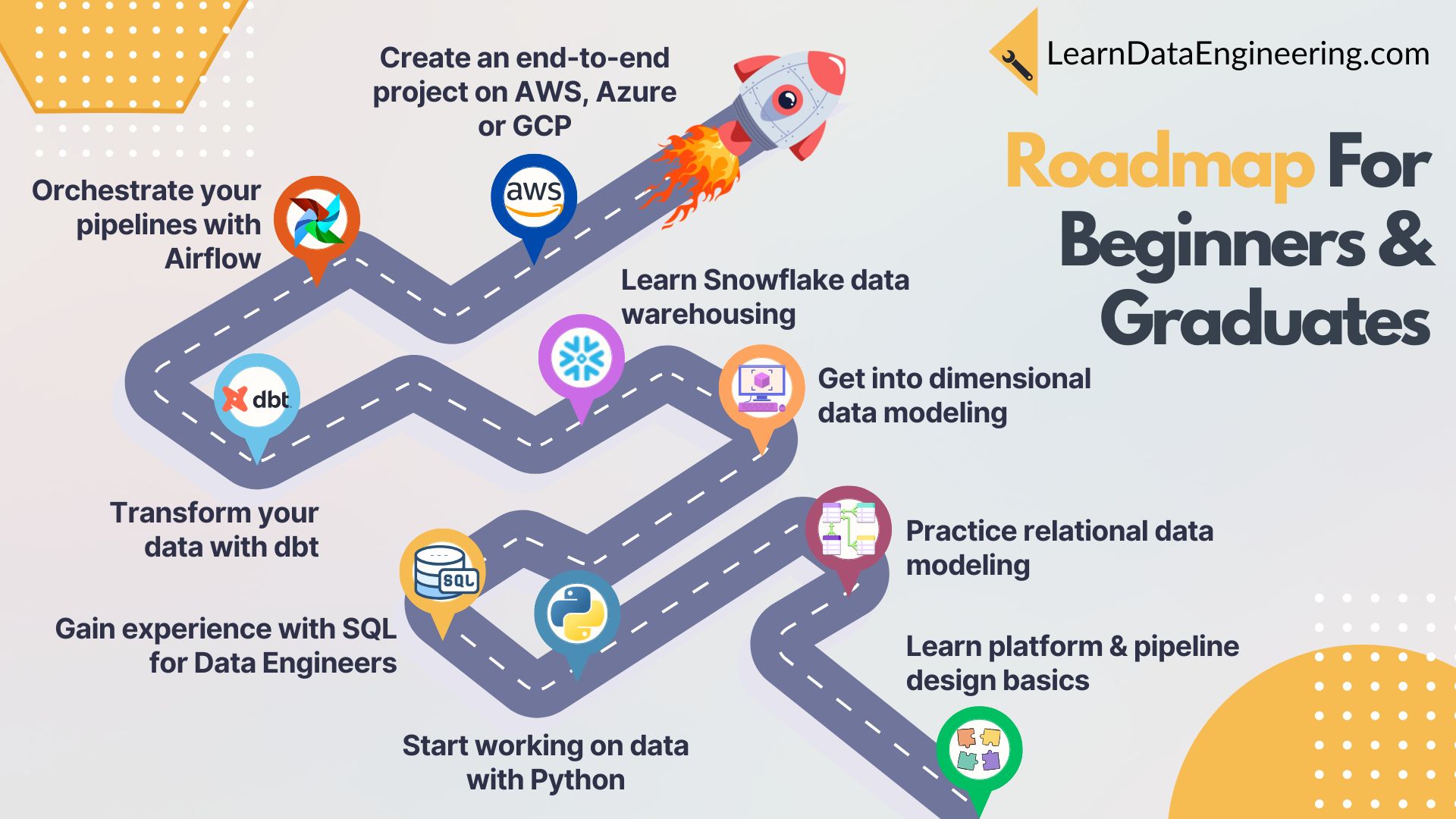
What You’ll Achieve in This Roadmap#
This roadmap is structured to help you understand the full data engineering workflow: from learning the fundamentals of data platforms and modeling to working with Python, SQL, and cloud-based ETL pipelines.
Learning Goals#
| Goal | Description |
|---|---|
| Goal #1 | Gain Experience in Data Platforms & Pipeline Design |
| Goal #2 | Work with Data Like a Data Engineer Using Python & SQL |
| Goal #3 | Learn Dimensional Data Modeling & Data Warehousing with Snowflake |
| Goal #4 | Gain Experience with ELT Using dbt & Orchestration with Airflow |
| Goal #5 | Build Your First ETL Pipeline on a Cloud Platform |
11-Week Learning Roadmap#
| Week | Topic | Key Learning Outcomes |
|---|---|---|
| Week 1 | Introduction & Platform & Pipeline Design | Understand data platforms, data pipelines, and the tools used in data engineering |
| Week 2 | Relational Data Modeling | Develop skills in creating relational data models for structured data |
| Week 3 & 4 | Python for Data Engineers | Learn Python for data processing, data manipulation, and pipeline development |
| Week 5 | Advanced SQL | Gain expertise in querying, storing, and manipulating data in relational databases |
| Week 6 | Dimensional Data Modeling | Master the techniques of dimensional modeling for analytics and reporting |
| Week 7 | Snowflake Data Warehousing | Learn how to use Snowflake as a cloud data warehouse |
| Week 8 | Data Transformation with dbt | Transform and model data efficiently using dbt |
| Week 9 | Data Pipeline Orchestration with Airflow | Automate and manage data workflows using Apache Airflow |
| Week 10 & 11 | End-to-End Project on AWS, Azure, or GCP | Complete an end-to-end project on a cloud platform of your choice |
Week 1: Introduction & Platform & Pipeline Design#
1. Learn the Basics of Platform & Pipeline Design#
Data Platform and Pipeline Design#
Learn how to build data pipelines with templates and examples for Azure, GCP, and Hadoop
Description#
Data pipelines are the backbone of any Data Science platform. They are essential for data ingestion, processing, and machine learning workflows. This training will help you understand how to create stream and batch processing pipelines as well as machine learning pipelines by going through the most essential basics—complemented by templates and examples for useful cloud computing platforms.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Platform & Pipeline Basics | The Platform Blueprint | 10:11 |
| Data Engineering Tools Guide | 2:44 | |
| End-to-End Pipeline Example | 6:18 | |
| Ingestion Pipelines | Push Ingestion Pipelines | 3:42 |
| Pull Ingestion Pipelines | 3:34 | |
| Pipeline Types | Batch Pipelines | 3:07 |
| Streaming Pipelines | 3:34 | |
| Visualization | Stream Analytics | 2:26 |
| Visualization Pipelines | 3:47 | |
| Visualization with Hive & Spark on Hadoop | 6:21 | |
| Visualization Data via Spark Thrift Server | 3:27 | |
| Platform Examples | AWS, Azure, GCP (Currently Slides Only) | START |
2. Get to Know the Different Data Stores#
Choosing Data Stores#
Learn the different types of data storages and when to use which
Description#
One part of creating a data platform and pipelines is to choose data stores, which is the focus of this training. You will learn about relational databases, NoSQL databases, data warehouses, and data lakes. The goal is to help you understand when to use each type of data storage and how to incorporate them into your pipeline.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| What are Data Stores? | 2:09 | |
| Data Stores Basics | OLTP vs OLAP | 7:34 |
| ETL vs ELT | 5:45 | |
| Data Stores Ranking | 4:05 | |
| Relational Databases | How to Choose Data Stores | 8:11 |
| Relational Databases Concepts | 6:34 | |
| NoSQL Databases | NoSQL Basics | 10:39 |
| Document Stores | 5:56 | |
| Time Series Databases | 5:00 | |
| Search Engines | 4:18 | |
| Wide Column Stores | 4:22 | |
| Key Value Stores | 4:59 | |
| Graph Databases | 1:05 | |
| Data Warehouses & Data Lakes | Data Warehouses | 5:32 |
| Data Lakes | 7:10 |
3. See Data Modeling Examples for the Learned Data Stores#
Data Modeling 1#
Learn how to design schemas for SQL, NoSQL, and Data Warehouses
Description#
Schema design is a critical skill for data engineers. This training covers schema design for different data stores using an e-commerce dataset. You will see examples of how the same dataset is modeled for relational databases, NoSQL stores, wide column stores, document stores, key-value stores, and data warehouses. This will help you understand how to create maintainable models and avoid data swamps.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Why Data Modeling Is Important | 5:44 | |
| A Good Dataset | 1:28 | |
| Relational Databases | Schema Design | 9:27 |
| Wide Column Stores | Schema Design | 7:35 |
| Document Stores | Schema Design | 7:28 |
| Key Value Stores | Schema Design | 4:49 |
| Data Warehouses | Schema Design | 4:44 |
| Data Modeling Workshop | November 2024 | 101:49 |
Week 2: Relational Data Modeling#
Start with Relational Data Modeling#
Relational Data modeling is an essential skill, as even in modern "big data" environments, relational databases are often used for managing and serving metadata. This week focuses on building a strong foundation in relational data modeling, which is crucial for structuring data effectively and optimizing query performance.
Relational Data Modeling#
Learn the most important basics to create a data model for OLTP data stores
Description#
This course covers everything you need to know about relational data modeling—from understanding entities, attributes, and relationships to normalizing data models up to the third normal form (3NF). You will learn how to design conceptual, logical, and physical data models, implement primary and foreign keys, and ensure data quality through constraints and validations. Practical exercises include setting up a MySQL server with Docker and creating ER diagrams using MySQL Workbench.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Basics and Prepare the Environment | Relational Data Models History | 3:16 |
| Installing MySQL Server and MySQL Workbench | 8:04 | |
| MySQL Workbench Introduction | 4:36 | |
| Create the Conceptual Data Model | The Design Process Explained | 4:14 |
| Discover the Entities | 10:24 | |
| Discover the Attributes | 13:09 | |
| Define Entity Relationships and Normalize the Data | 11:19 | |
| Defining and Resolving Relationships | Identifying vs Non-Identifying Relationships | 2:01 |
| How to Resolve Many-to-Many Relationships | 4:00 | |
| How to Resolve One-to-Many Relationships | 2:34 | |
| How to Resolve One-to-One Relationships | 1:45 | |
| Hands-On Workbench - Creating the Database | Create Your ER Diagram Using Workbench | 19:46 |
| Create a Physical Data Model | 4:13 | |
| Populate the MySQL DB with Data from .xls File | 15:13 |
Week 3 & 4: Python for Data Engineers#
Description#
This course offers a comprehensive guide to using Python for data engineering tasks. You’ll learn advanced Python features, including data processing with Pandas, working with APIs, interacting with PostgreSQL databases, and handling data types like JSON. The course also covers important programming concepts like exception handling, modules, unit testing, and object-oriented programming—all within the context of data engineering.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Advanced Python | Classes | 4:37 |
| Modules | 3:06 | |
| Exception Handling | 8:55 | |
| Logging | 5:12 | |
| Data Engineering | Datetime | 8:04 |
| JSON | 9:54 | |
| JSON Validation | 15:10 | |
| UnitTesting | 16:44 | |
| Pandas: Intro & Data Types | 8:43 | |
| Pandas: Appending & Merging DataFrames | 7:49 | |
| Pandas: Normalizing & Lambdas | 4:12 | |
| Pandas: Pivot & Parquet Write, Read | 6:17 | |
| Pandas: Melting & JSON Normalization | 8:15 | |
| Numpy | 4:47 | |
| Working with Data Sources/Sinks | Requests (Working with APIs) | 11:15 |
| Working with Databases: Setup | 4:06 | |
| Working with Databases: Tables, Bulk Load, Queries | 8:12 |
Week 5: SQL for Data Engineers#
Description#
SQL is the backbone of working with relational databases, and if you’re getting into Data Engineering, mastering SQL is a must. This course provides the essential SQL skills needed to work with databases effectively. You'll learn how to manage data, build efficient queries, and perform advanced operations to handle real-world data challenges.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Basics | Database Management Systems & SQL | 3:49 |
| The Chinook Database | 3:03 | |
| SQLite Installation | 7:02 | |
| DBeaver Installation | 4:08 | |
| Data Types in SQLite | 6:15 | |
| Basic SQL | DML & DDL | 15:06 |
| Select Statements | 6:03 | |
| Grouping & Aggregation | 10:12 | |
| Joins | 10:05 | |
| Advanced SQL | TCP Transaction Control Language | 6:42 |
| Common Table Expressions & Subqueries | 10:26 | |
| Window Functions 1: Concept & Syntax | 5:00 | |
| Window Functions 2: Aggregate Functions | 7:24 | |
| Window Functions 3: Ranking Functions | 6:05 | |
| Window Functions 4: Analytical Functions | 7:20 | |
| Optimization | Query Optimization | START |
| Indexing Best Practices | START |
Week 6: Dimensional Data Modeling#
Description#
Dimensional data modeling is a crucial skill for data engineers working with analytics use-cases where data needs to be structured efficiently for reporting and business insights. This course covers the basics of dimensional modeling, the medallion architecture, and how to create data models for OLAP data stores.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Data Warehousing Basics | 6:42 | |
| Dimensional Modeling Basics | Approaches to building a data warehouse | 5:20 |
| Dimension tables explained | 5:34 | |
| Fact tables explained | 6:34 | |
| Identifying dimensions | 3:16 | |
| Data Warehouse Setup | What is DuckDB | 5:58 |
| First DuckDB hands-on | 2:20 | |
| Creating tables in DuckDB | 2:40 | |
| Installing DBeaver | 6:49 | |
| Working With The Data Warehouse | Exploring SCD0 and SCD1 | 19:57 |
| Exploring SCD2 | 13:52 | |
| Exploring transaction fact table | 6:28 | |
| Exploring accumulating fact table | 7:17 |
Week 7: Snowflake for Data Engineers#
Description#
Snowflake is a highly popular cloud-based data warehouse that is ideal for beginners due to its simplicity and powerful features. In this course, you will learn how to set up Snowflake, load and process data, and create visualizations. The course covers both SQL and Python methods for managing data within Snowflake, and provides hands-on experience with connecting Snowflake to other tools such as PowerBI.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Introduction | Snowflake basics | 4:16 |
| Data Warehousing basics | 4:13 | |
| How Snowflake fits into data platforms | 3:14 | |
| Setup | Snowflake Account setup | 4:24 |
| Creating your warehouse & UI overview | 4:15 | |
| Loading CSVs from your PC | Our dataset & goals | 3:01 |
| Setup Snowflake database | 10:29 | |
| Preparing the upload file | 8:31 | |
| Using internal stages with SnowSQL | 12:37 | |
| Splitting a data table into two tables | 6:38 | |
| Visualizing Data | Creating a visualization worksheet | 7:08 |
| Creating a dashboard | 5:23 | |
| Connect PowerBI to Snowflake | 6:03 | |
| Query data with Python | 7:35 | |
| Automation | Create import task | 9:18 |
| Create table refresh task | 3:40 | |
| Test our pipeline | 3:14 | |
| AWS S3 Integration | Working with external stages for AWS S3 | 10:20 |
| Implementing snowpipe with S3 | 6:19 |
Week 8: dbt for Data Engineers#
Description#
This course introduces dbt (Data Build Tool), a SQL-first transformation workflow that allows you to transform, test, and document data directly within your data warehouse. You will learn how to set up dbt, connect it with Snowflake, create data pipelines, and implement advanced features like CI/CD and documentation generation. This training is ideal for data engineers looking to build trusted datasets for reporting, machine learning, and operational workflows.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| dbt Introduction & Setup | Modern data experience | 5:42 |
| Introduction to dbt | 4:38 | |
| Goals of this course | 4:50 | |
| Snowflake preparation | 7:29 | |
| Loading data into Snowflake | 4:48 | |
| Setup dbt Core | 9:35 | |
| Preparing the GitHub repository | 3:32 | |
| Working with dbt-Core | dbt models & materialization explained | 6:16 |
| Creating your first SQL model | 5:48 | |
| Working with custom schemas | 5:28 | |
| Creating your first Python model | 4:35 | |
| dbt sources | 1:55 | |
| Configuring sources | 4:03 | |
| Working with seed files | 4:20 | |
| Tests in dbt | Generic tests | 3:19 |
| Tests with Great Expectations | 3:25 | |
| Writing custom generic tests | 2:49 | |
| Working with dbt-Cloud | dbt cloud setup | 7:25 |
| Creating dbt jobs | 5:14 | |
| CI/CD automation with dbt cloud and GitHub | 10:52 | |
| Documentation in dbt | 7:38 |
Week 9: Apache Airflow Workflow Orchestration#
Description#
Airflow is a platform-independent workflow orchestration tool that offers many possibilities to create and monitor stream and batch pipeline processes. It supports complex, multi-stage processes across major platforms and tools in the data engineering world, such as AWS or Google Cloud. Airflow is not only great for planning and organizing your processes but also provides robust monitoring capabilities, allowing you to keep track of data workflows and troubleshoot effectively.
Check out this course in my Academy: Learn More
Detailed Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Airflow Workflow Orchestration | Airflow Usage | 3:19 |
| Airflow Fundamental Concepts | Fundamental Concepts | 2:47 |
| Airflow Architecture | 3:09 | |
| Example Pipelines | 4:49 | |
| Spotlight 3rd Party Operators | 2:17 | |
| Airflow XComs | 4:32 | |
| Hands-On Setup | Project Setup | 1:43 |
| Docker Setup Explained | 2:06 | |
| Docker Compose & Starting Containers | 4:23 | |
| Checking Services | 1:48 | |
| Setup WeatherAPI | 1:33 | |
| Setup Postgres DB | 1:58 | |
| Learn Creating DAGs | Airflow Webinterface | 4:37 |
| Creating DAG With Airflow 2.0 | 9:46 | |
| Running our DAG | 4:15 | |
| Creating DAG With TaskflowAPI | 6:59 | |
| Getting Data From the API With SimpleHTTPOperator | 3:38 | |
| Writing into Postgres | 4:12 | |
| Parallel Processing | 4:15 |
Week 10 & 11: End-to-End Project on AWS, Azure, or GCP#
Important: Choose One Project#
Participants need to select one of the following cloud platforms to complete their end-to-end data engineering project. It is not necessary to complete all three projects.
AWS Project Introduction#
The AWS project is designed for those who want to get started with cloud platforms, particularly with Amazon Web Services, the leading platform in data processing. This project will guide you through setting up an end-to-end data engineering pipeline using AWS tools like Lambda, API Gateway, Glue, Redshift, Kinesis, and DynamoDB. You will work with an e-commerce dataset, learn data modeling, and implement both stream and batch processing pipelines.
Check out this course in my Academy: Learn More
Detailed AWS Project Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Data Engineering | 4:15 | |
| Data Science Platform | 5:20 | |
| The Dataset | Data Types You Encounter | 3:03 |
| What Is A Good Dataset | 2:54 | |
| The Dataset We Use | 3:16 | |
| Defining The Purpose | 6:27 | |
| Relational Storage Possibilities | 3:46 | |
| NoSQL Storage Possibilities | 6:28 | |
| Platform Design | Selecting The Tools | 3:49 |
| Client | 3:05 | |
| Connect | 1:18 | |
| Buffer | 1:28 | |
| Process | 2:42 | |
| Store | 3:41 | |
| Visualize | 3:00 | |
| Data Pipelines | Data Ingestion Pipeline | 3:00 |
| Stream To Raw Storage Pipeline | 2:19 | |
| Stream To DynamoDB Pipeline | 3:09 | |
| Visualization API Pipeline | 2:56 | |
| Visualization Redshift Data Warehouse Pipeline | 5:29 | |
| Batch Processing Pipeline | 3:19 | |
| AWS Basics | Create An AWS Account | 1:58 |
| Things To Keep In Mind | 2:45 | |
| IAM Identity & Access Management | 4:06 | |
| Logging | 2:22 | |
| AWS Python API Boto3 | 2:57 | |
| Data Ingestion Pipeline | Development Environment | 4:02 |
| Create Lambda for API | 2:33 | |
| Create API Gateway | 8:30 | |
| Setup Kinesis | 1:38 | |
| Setup IAM for API | 5:00 | |
| Create Ingestion Pipeline (Code) | 6:09 | |
| Create Script to Send Data | 5:46 | |
| Test The Pipeline | 4:53 | |
| Stream To Raw S3 Storage Pipeline | Setup S3 Bucket | 3:42 |
| Configure IAM For S3 | 3:21 | |
| Create Lambda For S3 Insert | 7:16 | |
| Test The Pipeline | 4:01 | |
| Stream To DynamoDB Pipeline | Setup DynamoDB | 9:00 |
| Setup IAM For DynamoDB Stream | 3:36 | |
| Create DynamoDB Lambda | 9:20 | |
| Visualization API | Create API & Lambda For Access | 6:10 |
| Test The API | 4:47 | |
| Visualization Pipeline Redshift Data Warehouse | Setup Redshift Data Warehouse | 8:08 |
| Security Group For Firehose | 3:12 | |
| Create Redshift Tables | 5:51 | |
| S3 Bucket & jsonpaths.json | 3:02 | |
| Configure Firehose | 7:58 | |
| Debug Redshift Streaming | 7:43 | |
| Bug-fixing | 5:58 | |
| Power BI | 12:16 | |
| Batch Processing Pipeline | AWS Glue Basics | 5:14 |
| Glue Crawlers | 13:09 | |
| Glue Jobs | 13:43 | |
| Redshift Insert & Debugging | 7:16 |
Azure Project Introduction#
The Azure project is designed for those who want to build a streaming data pipeline using Microsoft Azure's robust cloud platform. This project introduces you to Azure services such as APIM, Blob Storage, Azure Functions, Cosmos DB, and Power BI. You will gain practical experience by building a pipeline that ingests, processes, stores, and visualizes data, using Python and Visual Studio Code.
Check out this course in my Academy: Learn More
Detailed Azure Project Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Project Introduction | Data Engineering in Azure - Streaming Data Pipelines | 2:43 |
| Datasets and Local Preprocessing | Introduction to Datasets and Local Preprocessing | 7:06 |
| Deploying Code on Visual Studio to Docker Containers | 5:27 | |
| Azure Functions and Blob Storage | Develop Azure Functions via Python and VS Code | 5:52 |
| Deploy Azure Function to Azure Function App and Test It | 6:26 | |
| Integrate Azure Function with Blob Storage via Bindings | 4:58 | |
| Add Azure Function to Azure API Management (APIM) | Expose Azure Function as a Backend | 7:05 |
| Securely Store Secrets in Azure Key Vault | 4:41 | |
| Add Basic Authentication in API Management | 4:35 | |
| Test APIM and Imported Azure Function via Local Python Program | 2:34 | |
| Create and Combine Event Hubs, Azure Function, and Cosmos DB | Create Event Hubs and Test Capture Events Feature | 6:59 |
| Modify Existing Azure Function to Include Event Hubs Binding | 6:42 | |
| Write Tweets to Cosmos DB (Core SQL) from Event Hub | Create a Cosmos DB (Core SQL) | 9:03 |
| Create a New Azure Function that Writes Messages to Cosmos DB | 9:03 | |
| Connect Power BI Desktop to Your Cosmos DB | Connect Power BI Desktop via Connector and Create a Dashboard | 6:32 |
GCP Project Introduction#
The GCP project is designed for those who want to learn how to build, manage, and optimize data pipelines on Google Cloud Platform. This project focuses on building an end-to-end pipeline that extracts data from an external weather API, processes it through GCP's data tools, and visualizes the results using Looker Studio. This project offers practical, hands-on experience with tools like Cloud SQL, Compute Engine, Cloud Functions, Pub/Sub, and Looker Studio.
Check out this course in my Academy: Learn More
Detailed GCP Project Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Introduction | Introduction | 1:13 |
| GitHub & the Team | 1:30 | |
| Data & Goals | Architecture of the Project | 3:19 |
| Introduction to Weather API | 2:18 | |
| Setup Google Cloud Account | 2:12 | |
| Project Setup | Creating the Project | 2:35 |
| Enabling the Required APIs | 1:34 | |
| Configure Scheduling | 2:20 | |
| Pipeline Creation - Extract from API | Setup VM for Database Interaction | 2:53 |
| Setup MySQL Database | 2:16 | |
| Setup VM Client and Create Database | 2:46 | |
| Creating Pub/Sub Message Queue | 1:41 | |
| Create Cloud Function to Pull Data from API | 4:17 | |
| Explanation of Code to Pull from API | 4:20 | |
| Pipeline Creation - Write to Database | Create Function to Write to Database | 7:47 |
| Explanation of Code to Write Data to Database | 5:56 | |
| Testing the Function | 5:51 | |
| Create Function Write Data to DB - Pull | 3:53 | |
| Explanation Code Write Data to DB - Pull | 4:33 | |
| Visualization | Setup Looker Studio and Create Bubble Chart | 2:20 |
| Setup Looker Studio and Create Time Series Chart | 1:57 | |
| Pipeline Monitoring | 6:20 |
What’s Next?#
After completing this roadmap, you’ll have the confidence and skills to not just analyze data but to engineer and optimize it like a pro! Explore advanced topics, start contributing to projects, and showcase your new skills to potential employers.
Roadmap for Data Analysts#
Start this roadmap at my Academy: Start Today
Go Beyond SQL and Learn How to Build, Automate, and Optimize Data Pipelines Like an Engineer#
Who Is This 10 Week Roadmap For?#
- Data Analysts who want to understand the full data lifecycle
- Those looking to move beyond SQL and build real data pipelines
- Professionals seeking hands-on, practical experience to boost their resumes
- Anyone wanting to stay competitive in the job market
What You’ll Achieve#
This roadmap provides a step-by-step approach to mastering data engineering skills. You'll start with Python and data modeling, move on to building pipelines, work with cloud platforms, and finally automate workflows using industry-standard tools.
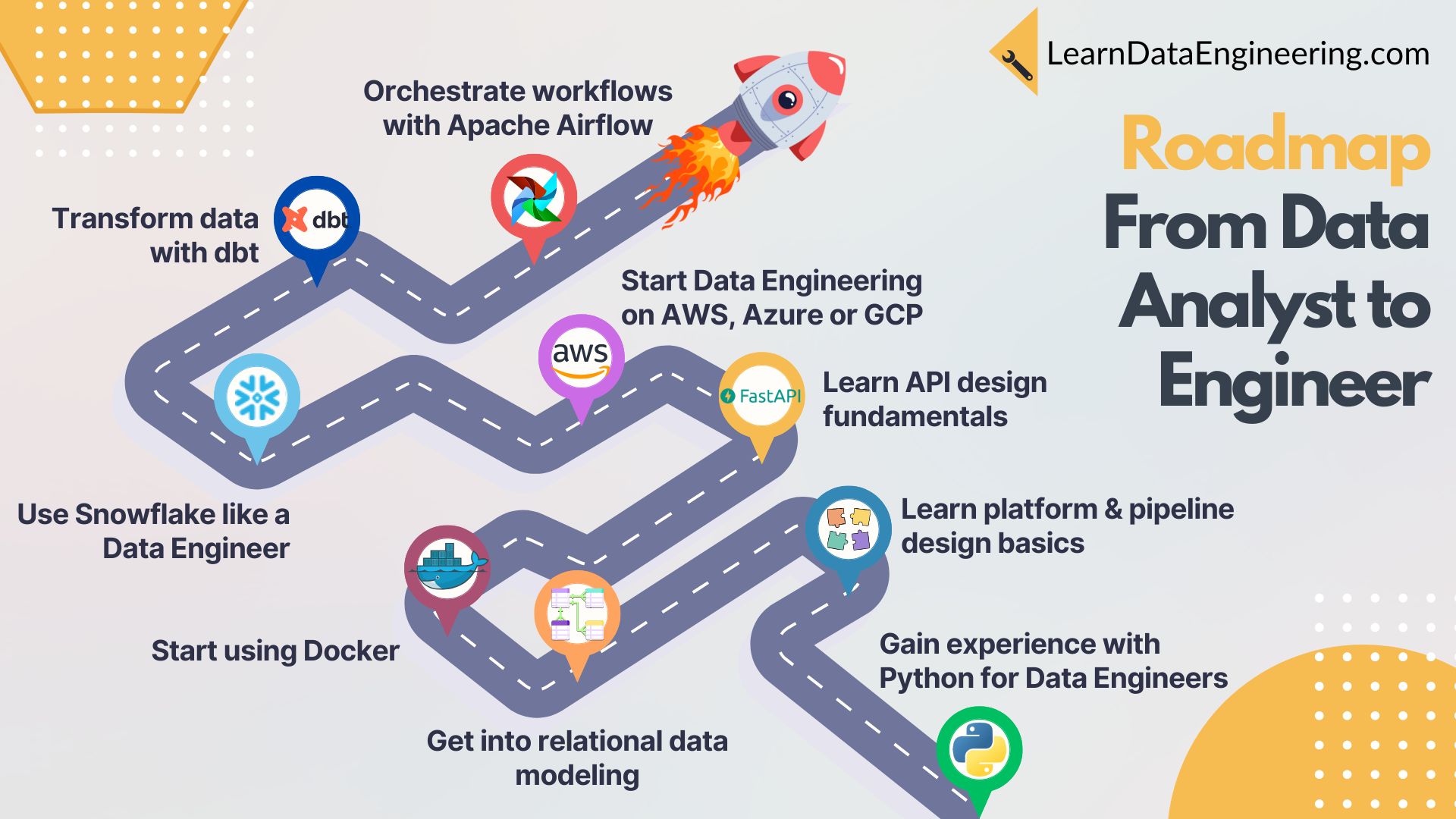
Learning Goals#
| Goal | Description |
|---|---|
| Goal #1 | Master Python & Relational Data Modeling |
| Goal #2 | Build Your First ETL Pipeline on AWS (or Azure/GCP) |
| Goal #3 | Gain Hands-On Experience with Snowflake & dbt |
| Goal #4 | Connect AWS and Snowflake |
| Goal #5 | Automate Your Data Pipeline with Airflow |
10-Week Learning Roadmap#
| Week | Topic | Key Learning Outcomes |
|---|---|---|
| Week 1 | Introduction to Data Engineering & Python | Understand core concepts of data engineering and Python programming basics |
| Week 2 | Platform & Pipeline Design | Learn how to design effective data platforms and pipelines |
| Week 3 | Relational Data Modeling | Develop skills in creating relational data models for structured data |
| Week 4 | Dimensional Data Modeling | Master the techniques of dimensional modeling for analytics and reporting |
| Week 5 | Docker Fundamentals & APIs | Get hands-on with containerization using Docker and working with APIs |
| Week 8 | Working with Snowflake | Gain practical experience using Snowflake as a data warehouse |
| Week 9 | Transforming Data With dbt | Learn to transform and model data efficiently using dbt |
| Week 10 | Pipeline Orchestration with Airflow | Automate and manage data workflows using Apache Airflow |
Detailed Weekly Content#
Week 1: Introduction to Data Engineering & Python#
If you want to take your data engineering skills to the next level, you are in the right place. Python has become the go-to language for data analysis and machine learning, and with our training, you will learn how to successfully use Python to build robust data pipelines and manipulate data efficiently.
This comprehensive training program is designed for data engineers of all levels. Whether you are just starting out in data engineering or you are an experienced engineer looking to expand your skill set, our Python for Data Engineers training will give you the tools you need to excel in your field.
At the end of the training, you will have a strong foundation in Python and data engineering and be ready to tackle complex data engineering projects with ease.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Classes | 4:37 |
| Modules | 3:06 |
| Exception Handling | 8:55 |
| Logging | 5:12 |
| Datetime | 8:04 |
| JSON | 9:54 |
| JSON Validation | 15:10 |
| UnitTesting | 16:44 |
| Pandas: Intro & data types | 8:43 |
| Pandas: Appending & Merging DataFrames | 7:49 |
| Pandas: Normalizing & Lambdas | 4:12 |
| Pandas: Pivot & Parquet write, read | 6:17 |
| Pandas: Melting & JSON normalization | 8:15 |
| Numpy | 4:47 |
| Requests (Working with APIs) | 11:15 |
| Working with Databases: Setup | 4:06 |
| Working with Databases: Tables, bulk load, queries | 8:12 |
Week 2: Platform & Pipeline Design#
Description#
Data pipelines are the number one thing within the Data Science platform. Without them, data ingestion or machine learning processing, for example, would not be possible.
This 110-minute long training will help you understand how to create stream and batch processing pipelines as well as machine learning pipelines by going through some of the most essential basics - complemented by templates and examples for useful cloud computing platforms.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Platform Blueprint & End to End Pipeline Example | 10:11 |
| Data Engineering Tools Guide | 2:44 |
| End to End Pipeline Example | 6:18 |
| Push Ingestion Pipelines | 3:42 |
| Pull Ingestion Pipelines | 3:34 |
| Batch Pipelines | 3:07 |
| Streaming Pipelines | 3:34 |
| Stream Analytics | 2:26 |
| Lambda Architecture | 4:02 |
| Visualization Pipelines | 3:47 |
| Visualization with Hive & Spark on Hadoop | 6:21 |
| Visualization Data via Spark Thrift Server | 3:27 |
Week 3: Relational Data Modeling#
Description#
Relational modeling is often used for building transactional databases. You might say, 'But I'm not planning to become a back-end engineer'. Apart from knowing how to move data, you should also know how to store it effectively which involves designing a scalable data model optimized to drive faster query response time and efficiently retrieve data.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Relational Data Models History | 3:16 |
| Installing MySQL Server and MySQL Workbench | 8:04 |
| MySQL Workbench Introduction | 4:36 |
| The Design Process Explained | 4:14 |
| Discover the Entities | 10:24 |
| Discover the Attributes | 13:09 |
| Define Entity Relationships and Normalize the Data | 11:19 |
| Identifying vs Non-identifying Relationships | 2:01 |
| Resolve Many-to-Many Relationships | 4:00 |
| Resolve One-to-Many Relationships | 2:34 |
| Resolve One-to-One Relationships | 1:45 |
| Create ER Diagram Using Workbench | 19:46 |
| Create a Physical Data Model | 4:13 |
| Populate MySQL DB with Data from .xls File | 15:13 |
| Course Conclusion | 1:28 |
Week 4: Dimensional Data Modeling#
Description#
In today’s data-driven world, efficient data organization is key to enabling insightful analysis and reporting. Dimensional data modeling is a crucial technique that helps structure your data for faster querying and better decision-making.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Intro to Data Warehousing | 6:42 |
| Approaches to Building a Data Warehouse | 5:20 |
| Dimension Tables Explained | 5:34 |
| Fact Tables Explained | 6:34 |
| Identifying Dimensions | 3:16 |
| What is DuckDB | 5:58 |
| First DuckDB Hands-on | 2:20 |
| Creating Tables in DuckDB | 2:40 |
| Installing DBeaver | 6:49 |
| Exploring SCD0 and SCD1 | 19:57 |
| Exploring SCD2 | 13:52 |
| Exploring Transaction Fact Table | 6:28 |
| Exploring Accumulating Fact Table | 7:17 |
| Course Conclusion | 0:52 |
Week 5: Docker Fundamentals & APIs#
Description#
Week 5 covers two crucial topics: containerization using Docker and building APIs with FastAPI. Docker is essential for creating lightweight, self-sustained containers, while APIs are the backbone of data platforms.
Check out Docker Fundamentals in my Academy: Learn More
Check out Building APIs with FastAPI in my Academy: Learn More
Course Curriculum#
Docker Fundamentals#
| Lesson | Duration |
|---|---|
| Docker vs Virtual Machines | 6:23 |
| Docker Terminology | 5:56 |
| Installing Docker Desktop | 4:09 |
| Pulling Images & Running Containers | 6:34 |
| Docker Compose | 6:34 |
| Build & Run Simple Image | 6:28 |
| Build Image with Dependencies | 5:05 |
| Using DockerHub Image Registry | 4:24 |
| Image Layers & Security Best Practices | 7:55 |
| Managing Docker with Portainer | 4:04 |
Building APIs with FastAPI#
| Lesson | Duration |
|---|---|
| What are APIs? | 8:29 |
| Hosting vs Using APIs | 4:08 |
| HTTP Methods & Media Types | 6:56 |
| API Parameters & Response Codes | 9:40 |
| Setting up FastAPI | 4:55 |
| Creating APIs: POST, GET, PUT | 16:18 |
| Testing APIs with Postman | 4:22 |
| Deploying FastAPI with Docker | 6:01 |
| API Security Best Practices | 3:48 |
Week 6 & 7: End-to-End Project on AWS, Azure, or GCP#
Important: Choose One Project#
Participants need to select one of the following cloud platforms to complete their end-to-end data engineering project. It is not necessary to complete all three projects.
AWS Project Introduction#
The AWS project is designed for those who want to get started with cloud platforms, particularly with Amazon Web Services, the leading platform in data processing. This project will guide you through setting up an end-to-end data engineering pipeline using AWS tools like Lambda, API Gateway, Glue, Redshift, Kinesis, and DynamoDB. You will work with an e-commerce dataset, learn data modeling, and implement both stream and batch processing pipelines.
Check out this project in my Academy: Learn More
Detailed AWS Project Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Data Engineering | 4:15 | |
| Data Science Platform | 5:20 | |
| The Dataset | Data Types You Encounter | 3:03 |
| What Is A Good Dataset | 2:54 | |
| The Dataset We Use | 3:16 | |
| Defining The Purpose | 6:27 | |
| Relational Storage Possibilities | 3:46 | |
| NoSQL Storage Possibilities | 6:28 | |
| Platform Design | Selecting The Tools | 3:49 |
| Client | 3:05 | |
| Connect | 1:18 | |
| Buffer | 1:28 | |
| Process | 2:42 | |
| Store | 3:41 | |
| Visualize | 3:00 | |
| Data Pipelines | Data Ingestion Pipeline | 3:00 |
| Stream To Raw Storage Pipeline | 2:19 | |
| Stream To DynamoDB Pipeline | 3:09 | |
| Visualization API Pipeline | 2:56 | |
| Visualization Redshift Data Warehouse Pipeline | 5:29 | |
| Batch Processing Pipeline | 3:19 | |
| AWS Basics | Create An AWS Account | 1:58 |
| Things To Keep In Mind | 2:45 | |
| IAM Identity & Access Management | 4:06 | |
| Logging | 2:22 | |
| AWS Python API Boto3 | 2:57 | |
| Data Ingestion Pipeline | Development Environment | 4:02 |
| Create Lambda for API | 2:33 | |
| Create API Gateway | 8:30 | |
| Setup Kinesis | 1:38 | |
| Setup IAM for API | 5:00 | |
| Create Ingestion Pipeline (Code) | 6:09 | |
| Create Script to Send Data | 5:46 | |
| Test The Pipeline | 4:53 | |
| Stream To Raw S3 Storage Pipeline | Setup S3 Bucket | 3:42 |
| Configure IAM For S3 | 3:21 | |
| Create Lambda For S3 Insert | 7:16 | |
| Test The Pipeline | 4:01 | |
| Stream To DynamoDB Pipeline | Setup DynamoDB | 9:00 |
| Setup IAM For DynamoDB Stream | 3:36 | |
| Create DynamoDB Lambda | 9:20 | |
| Visualization API | Create API & Lambda For Access | 6:10 |
| Test The API | 4:47 | |
| Visualization Pipeline Redshift Data Warehouse | Setup Redshift Data Warehouse | 8:08 |
| Security Group For Firehose | 3:12 | |
| Create Redshift Tables | 5:51 | |
| S3 Bucket & jsonpaths.json | 3:02 | |
| Configure Firehose | 7:58 | |
| Debug Redshift Streaming | 7:43 | |
| Bug-fixing | 5:58 | |
| Power BI | 12:16 | |
| Batch Processing Pipeline | AWS Glue Basics | 5:14 |
| Glue Crawlers | 13:09 | |
| Glue Jobs | 13:43 | |
| Redshift Insert & Debugging | 7:16 |
Azure Project Introduction#
The Azure project is designed for those who want to build a streaming data pipeline using Microsoft Azure's robust cloud platform. This project introduces you to Azure services such as APIM, Blob Storage, Azure Functions, Cosmos DB, and Power BI. You will gain practical experience by building a pipeline that ingests, processes, stores, and visualizes data, using Python and Visual Studio Code.
Check out this project in my Academy: Learn More
Detailed Azure Project Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Project Introduction | Data Engineering in Azure - Streaming Data Pipelines | 2:43 |
| Datasets and Local Preprocessing | Introduction to Datasets and Local Preprocessing | 7:06 |
| Deploying Code on Visual Studio to Docker Containers | 5:27 | |
| Azure Functions and Blob Storage | Develop Azure Functions via Python and VS Code | 5:52 |
| Deploy Azure Function to Azure Function App and Test It | 6:26 | |
| Integrate Azure Function with Blob Storage via Bindings | 4:58 | |
| Add Azure Function to Azure API Management (APIM) | Expose Azure Function as a Backend | 7:05 |
| Securely Store Secrets in Azure Key Vault | 4:41 | |
| Add Basic Authentication in API Management | 4:35 | |
| Test APIM and Imported Azure Function via Local Python Program | 2:34 | |
| Create and Combine Event Hubs, Azure Function, and Cosmos DB | Create Event Hubs and Test Capture Events Feature | 6:59 |
| Modify Existing Azure Function to Include Event Hubs Binding | 6:42 | |
| Write Tweets to Cosmos DB (Core SQL) from Event Hub | Create a Cosmos DB (Core SQL) | 9:03 |
| Create a New Azure Function that Writes Messages to Cosmos DB | 9:03 | |
| Connect Power BI Desktop to Your Cosmos DB | Connect Power BI Desktop via Connector and Create a Dashboard | 6:32 |
GCP Project Introduction#
The GCP project is designed for those who want to learn how to build, manage, and optimize data pipelines on Google Cloud Platform. This project focuses on building an end-to-end pipeline that extracts data from an external weather API, processes it through GCP's data tools, and visualizes the results using Looker Studio. This project offers practical, hands-on experience with tools like Cloud SQL, Compute Engine, Cloud Functions, Pub/Sub, and Looker Studio.
Check out this project in my Academy: Learn More
Detailed GCP Project Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Introduction | Introduction | 1:13 |
| GitHub & the Team | 1:30 | |
| Data & Goals | Architecture of the Project | 3:19 |
| Introduction to Weather API | 2:18 | |
| Setup Google Cloud Account | 2:12 | |
| Project Setup | Creating the Project | 2:35 |
| Enabling the Required APIs | 1:34 | |
| Configure Scheduling | 2:20 | |
| Pipeline Creation - Extract from API | Setup VM for Database Interaction | 2:53 |
| Setup MySQL Database | 2:16 | |
| Setup VM Client and Create Database | 2:46 | |
| Creating Pub/Sub Message Queue | 1:41 | |
| Create Cloud Function to Pull Data from API | 4:17 | |
| Explanation of Code to Pull from API | 4:20 | |
| Pipeline Creation - Write to Database | Create Function to Write to Database | 7:47 |
| Explanation of Code to Write Data to Database | 5:56 | |
| Testing the Function | 5:51 | |
| Create Function Write Data to DB - Pull | 3:53 | |
| Explanation Code Write Data to DB - Pull | 4:33 | |
| Visualization | Setup Looker Studio and Create Bubble Chart | 2:20 |
| Setup Looker Studio and Create Time Series Chart | 1:57 | |
| Pipeline Monitoring | 6:20 |
Week 8: Working with Snowflake#
Description#
Currently, Snowflake is the analytics store/data warehouse everybody is talking about. It is a 100% cloud-based platform that offers many advantages, including flexible data access and the ability to scale services as needed. Snowflake is widely used in the industry, and learning it will enhance your data engineering skill set.
This training covers everything from the basics of Snowflake and data warehousing to advanced integration and automation techniques. By the end, you will have the knowledge to prepare, integrate, manage data on Snowflake, and connect other systems to the platform.
Check out this course in my Academy: Learn More
Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Snowflake Basics | 4:16 | |
| Data Warehousing Basics | 4:13 | |
| How Snowflake Fits into Data Platforms | 3:14 | |
| Setup | Snowflake Account Setup | 4:24 |
| Creating Your Warehouse & UI Overview | 4:15 | |
| Loading CSVs from Your PC | Our Dataset & Goals | 3:01 |
| Setup Snowflake Database | 10:29 | |
| Preparing the Upload File | 8:31 | |
| Using Internal Stages with SnowSQL | 12:37 | |
| Splitting a Data Table into Two Tables | 6:38 | |
| Visualizing Data | Creating a Visualization Worksheet | 7:08 |
| Creating a Dashboard | 5:23 | |
| Connect PowerBI to Snowflake | 6:03 | |
| Query Data with Python | 7:35 | |
| Automation | Create Import Task | 9:18 |
| Create Table Refresh Task | 3:40 | |
| Test Our Pipeline | 3:14 | |
| AWS S3 Integration | Working with External Stages for AWS S3 | 10:20 |
| Implementing Snowpipe with S3 | 6:19 |
Week 9: Transforming Data With dbt#
Description#
dbt is a SQL-first transformation workflow that simplifies the process of transforming, testing, and documenting data. It allows teams to work directly within the data warehouse, creating trusted datasets for reporting, machine learning, and operational workflows. This training is the perfect starting point to get hands-on experience with dbt Core, dbt Cloud, and Snowflake.
Check out this course in my Academy: Learn More
Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| dbt Introduction & Setup | Modern Data Experience | 5:42 |
| Introduction to dbt | 4:38 | |
| Goals of this Course | 4:50 | |
| Snowflake Preparation | 7:29 | |
| Loading Data into Snowflake | 4:48 | |
| Setup dbt Core | 9:35 | |
| Preparing the GitHub Repository | 3:32 | |
| Working with dbt-Core | dbt Models & Materialization Explained | 6:16 |
| Creating Your First SQL Model | 5:48 | |
| Working with Custom Schemas | 5:28 | |
| Creating Your First Python Model | 4:35 | |
| dbt Sources | 1:55 | |
| Configuring Sources | 4:03 | |
| Working with Seed Files | 4:20 | |
| Tests in dbt | Generic Tests | 3:19 |
| Tests with Great Expectations | 3:25 | |
| Writing Custom Generic Tests | 2:49 | |
| Working with dbt-Cloud | dbt Cloud Setup | 7:25 |
| Creating dbt Jobs | 5:14 | |
| CI/CD Automation with dbt Cloud and GitHub | 10:52 | |
| Documentation in dbt | 7:38 |
Week 10: Pipeline Orchestration with Airflow#
Description#
Apache Airflow is a powerful, platform-independent workflow orchestration tool widely used in the data engineering world. It allows you to create and monitor both stream and batch pipeline processes with ease. Airflow supports integration with major platforms and tools such as AWS, Google Cloud, and many more.
Airflow not only helps in planning and organizing workflows but also offers robust monitoring features, allowing you to troubleshoot and maintain complex ETL pipelines effectively. As one of the most popular tools for workflow orchestration, mastering Airflow is highly valuable for data engineers.
Check out this course in my Academy: Learn More
Course Curriculum#
| Module | Lesson | Duration |
|---|---|---|
| Airflow Workflow Orchestration | Airflow Usage | 3:19 |
| Airflow Fundamental Concepts | Fundamental Concepts | 2:47 |
| Airflow Architecture | 3:09 | |
| Example Pipelines | 4:49 | |
| Spotlight 3rd Party Operators | 2:17 | |
| Airflow XComs | 4:32 | |
| Hands-On Setup | Project Setup | 1:43 |
| Docker Setup Explained | 2:06 | |
| Docker Compose & Starting Containers | 4:23 | |
| Checking Services | 1:48 | |
| Setup WeatherAPI | 1:33 | |
| Setup Postgres DB | 1:58 | |
| Learn Creating DAGs | Airflow Webinterface | 4:37 |
| Creating DAG With Airflow 2.0 | 9:46 | |
| Running our DAG | 4:15 | |
| Creating DAG With TaskflowAPI | 6:59 | |
| Getting Data From the API With SimpleHTTPOperator | 3:38 | |
| Writing into Postgres | 4:12 | |
| Parallel Processing | 4:15 | |
| Recap | Recap & Outlook | 4:38 |
What’s Next?#
After completing this roadmap, you’ll have the confidence and skills to not just analyze data but to engineer and optimize it like a pro! Explore advanced topics, start contributing to projects, and showcase your new skills to potential employers.
Roadmap for Data Scientists#
14-Week Data Engineering Roadmap for Data Scientists#
From Notebooks to Production: Build, Deploy, and Scale Your ML Workflows#
Start this roadmap at my Academy: Start Today#
Who Is This Roadmap For?#
- Data Scientists who want to deploy and maintain ML models in production
- ML practitioners struggling with real-time data, CI/CD, and orchestration
- Data professionals looking to expand their engineering toolkit
- Anyone ready to go beyond notebooks and automate their ML workflows
What You’ll Achieve#
This roadmap provides a step-by-step approach to gaining production-grade data engineering skills. You'll start with pipelines and containerization, move on to deployment and orchestration, and finish with big data and monitoring.
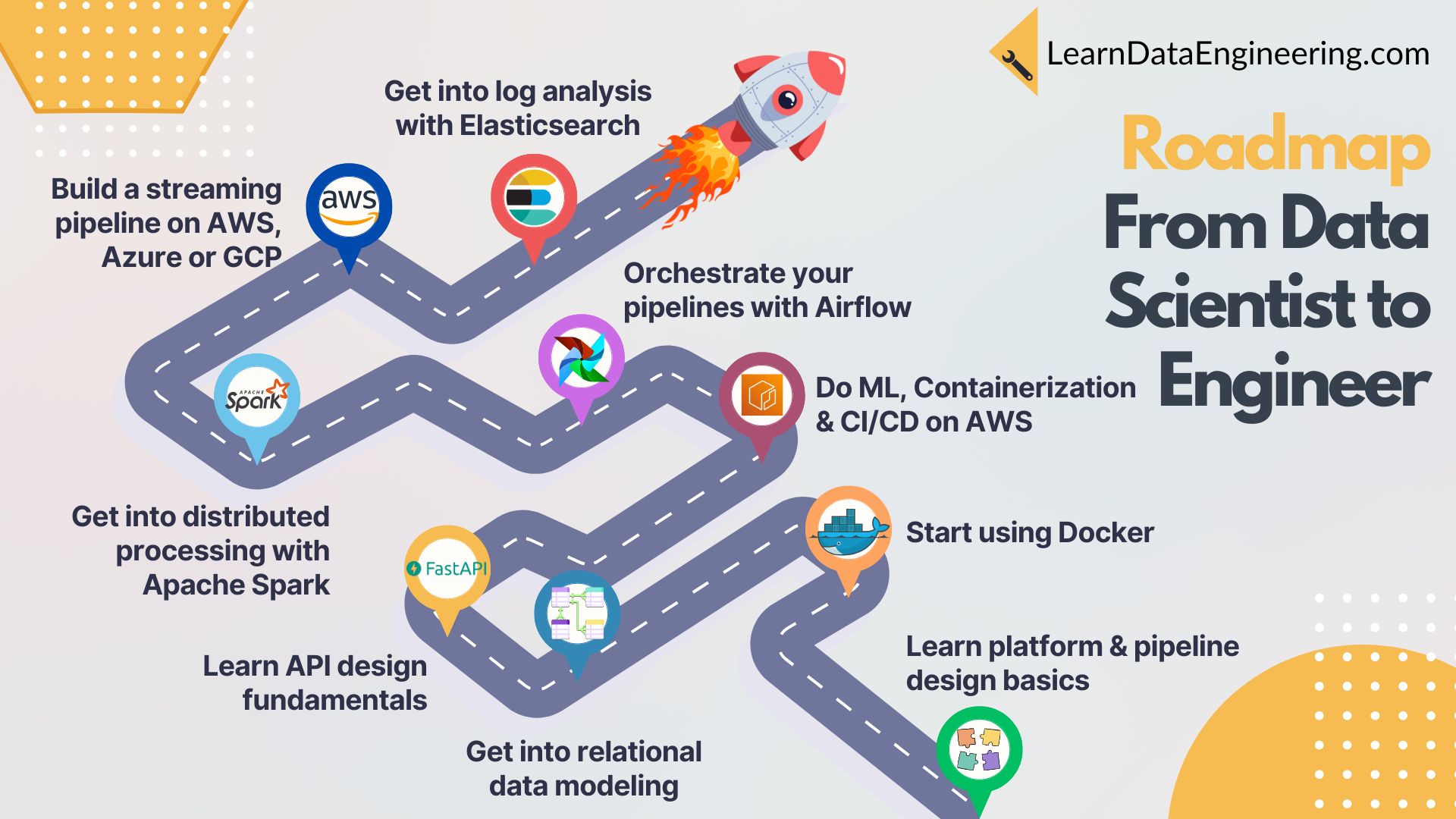
Learning Goals#
| Goal # | Description |
|---|---|
| Goal #1 | Build an End-to-End ML Pipeline on AWS |
| Goal #2 | Add CI/CD & Containerization to Your Platform |
| Goal #3 | Implement the Lakehouse Architecture in AWS or GCP |
| Goal #4 | Orchestrate Your Pipelines with Airflow |
| Goal #5 | Process Big Data with Apache Spark & Streaming |
| Goal #6 | Analyze Your ML Training Logs with Elasticsearch |
14-Week Learning Roadmap#
| Week | Topic |
|---|---|
| Week 1 | Platform & Pipeline Design |
| Week 2 | Docker Fundamentals |
| Week 3 | Relational Data Modeling |
| Week 4 | Working & Designing APIs |
| Week 5 & 6 | ML & Containerization on AWS |
| Week 7 | ETL & CI/CD on AWS |
| Week 8 | Building a Lakehouse on AWS or GCP |
| Week 9 | Orchestrate with Airflow |
| Week 10 | Pre-Process Data with Apache Spark |
| Week 11-13 | Build a Streaming Pipeline (AWS, Azure, GCP) |
| Week 14 | Analyze Training Logs with Elasticsearch |
Week 1: Platform & Pipeline Design#
Description#
Data pipelines are the foundation of any data platform. In this 110-minute training, you'll learn about stream, batch, and ML pipelines. You'll also explore platform blueprints, architecture components, and Lambda architecture.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Platform Blueprint & End to End Pipeline Example | 10:11 |
| Data Engineering Tools Guide | 2:44 |
| End to End Pipeline Example | 6:18 |
| Push Ingestion Pipelines | 3:42 |
| Pull Ingestion Pipelines | 3:34 |
| Batch Pipelines | 3:07 |
| Streaming Pipelines | 3:34 |
| Stream Analytics | 2:26 |
| Lambda Architecture | 4:02 |
| Visualization Pipelines | 3:47 |
| Visualization with Hive & Spark on Hadoop | 6:21 |
| Visualization Data via Spark Thrift Server | 3:27 |
| Platform Examples (AWS, Azure, GCP, Hadoop) | Slides Only |
Week 2: Docker Fundamentals#
Description#
Docker is the go-to container platform for engineers. This training covers key concepts, hands-on Docker usage, building and running containers, and how Docker fits into production workflows.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Docker vs Virtual Machines | 6:23 |
| Docker Terminology | 5:56 |
| Installing Docker Desktop | 4:09 |
| Pulling Images & Running Containers | 6:34 |
| CLI Cheat Sheet | 3:38 |
| Docker Compose Explained | 6:34 |
| Build & Run Hello World Image | 6:28 |
| Build Image with Dependencies | 5:05 |
| Using DockerHub | 4:24 |
| Image Layers | 7:55 |
| Deployment in Production | 5:47 |
| Security Best Practices | 4:09 |
| Managing Docker with Portainer | 4:04 |
Week 3: Relational Data Modeling#
Description#
Learn how to design efficient and scalable relational models. You'll go through conceptual to physical modeling and normalize your schema. You'll use MySQL and MySQL Workbench for hands-on practice.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| History of Relational Models | 3:16 |
| Installing MySQL & Workbench | 8:04 |
| Workbench Introduction | 4:36 |
| The Design Process Explained | 4:14 |
| Discover Entities | 10:24 |
| Discover Attributes | 13:09 |
| Normalize & Define Relationships | 11:19 |
| Identifying vs Non-identifying | 2:01 |
| Resolve Many-to-Many | 4:00 |
| Resolve One-to-Many | 2:34 |
| Resolve One-to-One | 1:45 |
| Create ER Diagram | 19:46 |
| Create Physical Data Model | 4:13 |
| Populate from XLS | 15:13 |
| Course Conclusion | 1:28 |
Week 4: Working & Designing APIs#
Description#
APIs are the backbone of modern data platforms. You'll learn how to build and test APIs using FastAPI, design schemas, and deploy them in Docker. Postman and Docker are used for testing and deployment.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| What are APIs? | 8:29 |
| Hosting vs Using APIs | 4:08 |
| HTTP Methods & Media Types | 6:56 |
| Response Codes & Parameters | 9:40 |
| FastAPI Setup | 4:55 |
| POST, GET, PUT API Methods | 16:18 |
| Testing with Postman | 4:22 |
| Deploying FastAPI with Docker | 6:01 |
| API Security Best Practices | 3:48 |
Week 5 & 6: ML & Containerization on AWS#
Description#
This hands-on project teaches you how to build a real-time ML pipeline on AWS. You'll pull data from the Twitter API (or The Guardian API), apply sentiment analysis with NLTK in a Lambda function, store results in a Postgres database via RDS, and build a Streamlit dashboard. Finally, you’ll containerize and deploy the dashboard using AWS ECS and ECR.
Check out this project in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Introduction | 2:38 |
| Project Architecture Explained | 2:06 |
| RDS Setup | 2:37 |
| VPC Inbound Rules | 2:12 |
| PG Admin Installation & S3 Config | 4:05 |
| Lambda Intro & IAM Setup | 3:11 |
| Create Lambda Function | 1:24 |
| Lambda Code Explained | 8:22 |
| Insert Code Into Lambda | 0:56 |
| Add Layers from Klayers | 5:32 |
| Create Custom Layers | 4:40 |
| Test Lambda & Set Env Variables | 4:53 |
| Schedule Lambda with EventBridge | 3:15 |
| Setup Virtual Conda Environment | 4:07 |
| Install Dependencies with Poetry | 5:57 |
| Streamlit App Code Walkthrough | 7:52 |
| Setup ECR Container Registry | 1:52 |
| AWS CLI Install & Login | 5:19 |
| Dockerfile Build & Push | 2:52 |
| Create ECS Fargate Cluster | 1:34 |
| ECS Task Configuration & Deployment | 4:59 |
| Fixing ECS Task | 5:14 |
| Stop ECS Task | 0:59 |
| Project Conclusion | 5:06 |
Week 7: ETL & CI/CD on AWS#
Description#
In this project, you'll build a lightweight ETL job that pulls data from a public weather API and writes it into a time series database. You’ll dockerize the job, schedule it using AWS Lambda and EventBridge, and visualize the data using Grafana.
Check out this project in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Quick Note from Andreas | 0:43 |
| Project Introduction | 1:26 |
| Setup of the Project | 2:52 |
| Time Series Data Basics | 2:20 |
| Big Pros of Time Series Databases | 2:06 |
| About TDengine | 1:22 |
| Setup Weather API | 1:04 |
| Code Query API | 2:41 |
| TDengine Setup | 3:04 |
| Connect Python to TDengine | 1:50 |
| Lambda Docker Container & Push to ECR | 1:55 |
| AWS Setup | 1:36 |
| Create Lambda Function Using Docker Image | 1:04 |
| Schedule Function with EventBridge | 1:25 |
| CloudWatch Lambda Events | 0:27 |
| Grafana Setup | 3:01 |
Week 8: Building a Lakehouse on AWS or GCP#
Description#
This week, you’ll learn how to combine data lakes and warehouses into a Lakehouse architecture. You’ll implement a full data analytics stack using tools like S3, Athena, BigQuery, Glue, Quicksight, and Data Studio.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Introduction | 2:13 |
| Data Science Platform Overview | 4:10 |
| ETL & ELT in Warehouses | 6:22 |
| Data Lake & Warehouse Integration | 3:29 |
| GCP Pipelines Overview | 3:13 |
| Cloud Storage & BigQuery Hands-on | 8:35 |
| Create Dashboard in Data Studio | 7:33 |
| GCP Recap & AWS Goals | 2:12 |
| Upload Data to S3 | 2:12 |
| Athena Manual Table Configuration | 3:48 |
| Create Dashboard in Quicksight | 5:05 |
| Athena via Glue Catalog | 3:29 |
| Course Recap | 2:36 |
| BONUS: Redshift Spectrum with S3 | 2:57 |
Week 9: Orchestrate with Airflow#
Description#
This training will guide you through installing and running Apache Airflow in Docker, creating DAGs, using the Taskflow API, and monitoring workflow execution.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Introduction | 1:36 |
| Airflow Usage | 3:19 |
| Fundamental Concepts | 2:47 |
| Airflow Architecture | 3:09 |
| Example Pipelines | 4:49 |
| Spotlight on 3rd Party Operators | 2:17 |
| Airflow XComs | 4:32 |
| Project Setup | 1:43 |
| Docker Setup Explained | 2:06 |
| Docker Compose & Starting Containers | 4:23 |
| Checking Services | 1:48 |
| Weather API Setup | 1:33 |
| Postgres DB Setup | 1:58 |
| Airflow Web Interface | 4:37 |
| Create DAG with Airflow 2.0 | 9:46 |
| Run Your DAG | 4:15 |
| Create DAG with Taskflow API | 6:59 |
| Get Data via SimpleHTTP Operator | 3:38 |
| Write to Postgres | 4:12 |
| Parallel Processing | 4:15 |
| Recap & Outlook | 4:38 |
Week 10: Pre-Process Data with Apache Spark#
Description#
This training introduces Apache Spark fundamentals, showing you how to process large datasets using Spark DataFrames, RDDs, and SparkSQL inside Docker and Jupyter Notebooks.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Introduction & Contents | 3:30 |
| Vertical vs Horizontal Scaling | 3:55 |
| What Spark Is Good For | 4:45 |
| Driver, Context & Executors | 4:11 |
| Cluster Types | 1:59 |
| Client vs Cluster Deployment | 6:11 |
| Where to Run Spark | 3:38 |
| Tools in Spark Course | 2:35 |
| Dataset Overview | 4:11 |
| Docker Setup | 2:52 |
| Jupyter Notebook Setup & Run | 5:31 |
| RDDs | 3:57 |
| DataFrames | 1:40 |
| Transformations & Actions Overview | 2:59 |
| Transformations | 2:22 |
| Actions | 3:06 |
| JSON Transformations | 9:52 |
| Working with Schemas | 8:23 |
| Working with DataFrames | 10:09 |
| SparkSQL | 5:04 |
| Working with RDDs | 12:52 |
Week 11–13: Build a Streaming Pipeline on AWS, Azure, or GCP#
Description#
In this 3-week section, you'll complete an end-to-end streaming data project on the cloud platform of your choice: AWS, Azure, or GCP. Each project teaches you how to ingest real-time data, process it, store it, and create visualizations.
You only need to complete one of the following three options:
Option 1: Streaming Pipeline on AWS#
Description#
You'll use AWS services like API Gateway, Kinesis, DynamoDB, Redshift, Lambda, Glue, and Power BI to create a complete streaming solution. You'll work with e-commerce data and build multiple ingestion and batch pipelines.
Check out this project in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Data Engineering | 4:15 |
| Data Science Platform | 5:20 |
| Dataset Introduction | 3:16 |
| Relational Storage Possibilities | 3:46 |
| NoSQL Storage Possibilities | 6:28 |
| Platform Design & Pipeline Planning | 3:49 |
| Client to Visualization Design | 3:00 |
| Data Ingestion to Kinesis | 3:00 |
| Stream to S3 and DynamoDB | 5:28 |
| Visualization API & Redshift | 5:29 |
| AWS Setup & IAM | 4:06 |
| Create Lambda Functions | 2:33 |
| Configure Firehose & Debugging | 7:43 |
| Power BI Setup | 12:16 |
| Glue Crawlers and Jobs | 26:52 |
Option 2: Streaming Pipeline on Azure#
Description#
You’ll build a Twitter-like JSON stream pipeline using Azure Functions, Event Hub, Cosmos DB, and Power BI. You’ll learn how to set up API management, key vaults, and authentication.
Check out this project in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Project Introduction | 2:43 |
| Local Preprocessing & Docker Setup | 7:06 |
| Develop & Deploy Azure Functions | 5:52 |
| Test Functions & Integrate with Blob Storage | 6:26 |
| Add Functions to Azure API Management (APIM) | 7:05 |
| Key Vault & Authentication | 4:41 |
| Create Event Hubs and Bindings | 6:59 |
| Write to Cosmos DB | 9:03 |
| Power BI Connection and Dashboard Creation | 6:32 |
Option 3: Streaming Pipeline on GCP#
Description#
This project shows how to extract weather data via API, stream it with Pub/Sub, write it into Cloud SQL, and visualize it with Looker Studio. You'll also learn function deployment and VM/database setup.
Check out this project in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Introduction & Setup | 2:43 |
| Architecture & Weather API | 5:31 |
| Enable APIs & Configure Scheduling | 4:00 |
| Setup MySQL Database & Compute Engine | 4:40 |
| Create Cloud Functions for Data Ingestion | 8:37 |
| Use Pub/Sub for Messaging | 1:41 |
| Write Data to Cloud SQL | 13:43 |
| Test and Monitor Data Flow | 5:51 |
| Setup Looker Studio & Build Dashboards | 4:17 |
| Monitor Pipelines | 6:20 |
Week 14: Analyze Training Logs with Elasticsearch#
Description#
Wrap up your roadmap by learning how to monitor pipelines using Elasticsearch. You’ll deploy Elasticsearch with Docker, send logs from your training pipelines, and visualize them in Kibana dashboards.
Check out this course in my Academy: Learn More
Course Curriculum#
| Lesson | Duration |
|---|---|
| Course Introduction | 2:07 |
| Elasticsearch vs Relational Databases | 5:43 |
| ETL Log Analysis & Debugging | 3:54 |
| Streaming Log Analysis & Debugging | 2:48 |
| Solving Problems with Elasticsearch | 4:37 |
| ELK Stack Overview | 2:03 |
| Setup Limiting RAM & Environment Config | 4:26 |
| Running Elasticsearch | 4:07 |
| Elasticsearch APIs & Python Index Creation | 7:31 |
| Write Logs (JSON) to Elasticsearch | 4:46 |
| Create Kibana Visualizations & Dashboards | 9:27 |
| Search Logs in Elasticsearch | 4:57 |
| Course Recap | — |
What’s Next?#
After 14 weeks, you’ll have built scalable, production-ready data pipelines and ML workflows. You can now explore more advanced projects, optimize performance, and contribute to production systems with confidence. Need help showcasing your skills or getting hired? Reach out to my coaching program!
Roadmap for Software Engineers#
if you're transitioning from a background in computer science or software engineering into data engineering, you're already equipped with a solid foundation. Your existing knowledge in coding, familiarity with SQL databases, understanding of computer networking, and experience with operating systems like Linux, provide you with a considerable advantage. These skills form the cornerstone of data engineering and can significantly streamline your learning curve as you embark on this new journey.
Here's a refined roadmap, incorporating your prior expertise, to help you excel in data engineering:
- Deepen Your Python Skills: Python is crucial in data engineering for processing and handling various data formats, such as APIs, CSV, and JSON. Given your coding background, focusing on Python for data engineering will enhance your ability to manipulate and process data effectively.
- Master Docker: Docker is essential for deploying code and managing containers, streamlining the software distribution process. Your understanding of operating systems and networking will make mastering Docker more intuitive, as you'll appreciate the importance of containerization in today's development and deployment workflows.
- Platform and Pipeline Design: Leverage your knowledge of computer networking and operating systems to grasp the architecture of data platforms. Understanding how to design data pipelines, including considerations for stream and batch processing, and emphasizing security, will be key. Your background will provide a solid foundation for understanding how different components integrate within a data platform.
- Choosing the Right Data Stores: Dive into the specifics of data stores, understanding the nuances between transactional and analytical databases, and when to use relational vs. NoSQL vs. document stores vs. time-series databases. Your experience with SQL databases will serve as a valuable baseline for exploring these various data storage options.
- Explore Cloud Platforms: Get hands-on with cloud services such as AWS, GCP, and Azure. Projects or courses that offer practical experience with these platforms will be invaluable. Your tasks might include building pipelines to process data from APIs, using message queues, or delving into data warehousing and lakes, capitalizing on your foundational skills.
- Optional Deep Dives: For those interested in advanced data processing, exploring technologies like Spark or Kafka for stream processing can be enriching. Additionally, learning how to build APIs and work with MongoDB for document storage can open new avenues, especially through practical projects.
- Log Analysis and Data Observability: Familiarize yourself with tools like Elasticsearch, Grafana, and InfluxDB to monitor and analyze your data pipelines effectively. This area leverages your comprehensive understanding of how systems communicate and operate, enhancing your ability to maintain and optimize data flows.
As you embark on this path, remember that your journey is unique. Your existing knowledge not only serves as a strong foundation but also as a catalyst for accelerating your growth in the realm of data engineering. Keep leveraging your strengths, explore areas of interest deeply, and continually adapt to the evolving landscape of data technology.
| Live Stream -> Data Engineering Roadmap for Computer Scientists / Developers |------------------| |In this live stream you'll find even more details how to read this roadmap for Data Scientists, why I chose these tools and why I think this is the right way to do it. | Watch on YouTube|
Data Engineers Skills Matrix#
If you're diving into the world of data engineering or looking to climb the ladder within this field, you're in for a treat with this enlightening YouTube video. Andreas kicks things off by introducing us to a very handy tool they've developed: the Data Engineering Skills Matrix. This isn't just any chart; it's a roadmap designed to navigate the complex landscape of data engineering roles, ranging from a Junior Data Engineer to the lofty heights of a Data Architect and Machine Learning Engineer.
| Live Stream -> Data Engineering Skills Matrix
|------------------|
|In this live stream you'll find even more details how to read this skills matrix for Data Engineers.
| Watch on YouTube|
Andreas takes us through the intricacies of this matrix, layer by layer. Starting with the basics, they discuss the minimum experience needed for each role. It's an eye-opener, especially when you see how experience requirements evolve from a beginner to senior levels. But it's not just about how many years you've spent in the field; it's about the skills you've honed during that time.
Challenges & Responsibilities#
As the conversation progresses, Andreas delves into the core responsibilities and main tasks associated with each role. You'll learn what sets a Junior Data Engineer apart from a Senior Data Engineer, the unique challenges a Data Architect faces, and the critical skills a Machine Learning Engineer must possess. This part of the video is golden for anyone trying to understand where they fit in the data engineering ecosystem or plotting their next career move.
SQL & Soft Skills#
Then there's the talk on SQL knowledge and its relevance across different roles. This segment sheds light on how foundational SQL is, irrespective of your position. But it's not just about technical skills; the video also emphasizes soft skills, like leadership and collaboration, painting a holistic picture of what it takes to succeed in data engineering.
For those who love getting into the weeds, Andreas doesn't disappoint. They discuss software development skills, debugging, and even dive into how data engineers work with SQL and databases. This part is particularly insightful for understanding the technical depth required at various stages of your career.
Q&A#
And here's the cherry on top: Andreas encourages interaction, inviting viewers to share their experiences and questions. This makes the video not just a one-way learning experience but a dynamic conversation that enriches everyone involved.
Summary#
By the end of this video, you'll walk away with a clear understanding of the data engineering field's diverse roles. You'll know the skills needed to excel in each role and have a roadmap for your career progression. Whether you're a recent graduate looking to break into data engineering or a seasoned professional aiming for a senior position, Andreas's video is a must-watch. It's not just a lecture; it's a guide to navigating the exciting world of data engineering, tailored by someone who's taken the time to lay out the journey for you.
How to Become a Senior Data Engineer#
Becoming a senior data engineer is a goal many in the tech industry aspire to. It's a role that demands a deep understanding of data architecture, advanced programming skills, and the ability to lead and communicate effectively within an organization. In this live stream series, I dove into what it takes to climb the ladder to a senior data engineering position. Here are the key takeaways. You can find the links to the videos and the shown images below.
Understanding the Role#
The journey to becoming a senior data engineer starts with a clear understanding of what the role entails. Senior data engineers are responsible for designing, implementing, and maintaining an organization's data architecture. They ensure data accuracy, accessibility, and security, often taking the lead on complex projects that require advanced technical skills and strategic thinking.
Key Skills and Knowledge Areas#
Based on insights from the live stream and consultations with industry experts, including GPT-3, here are the critical areas where aspiring senior data engineers should focus their development:
- Advanced Data Modeling and Architecture: Mastery of data modeling techniques and architecture best practices is crucial. This includes understanding of dimensional and Data Vault modeling, as well as expertise in SQL and NoSQL databases.
- Big Data Technologies: Familiarity with distributed computing frameworks (like Apache Spark), streaming technologies (such as Apache Kafka), and cloud-based big data technologies is essential. Advanced ETL Techniques: Skills in incremental loading, data merging, and transformation are vital for efficiently processing large datasets.
- Data Warehousing and Data Lake Implementation: Building and maintaining scalable and performant data warehouses and lakes are fundamental responsibilities.
- Cloud Computing: Proficiency in cloud services from AWS, Azure, or GCP, along with platforms like Snowflake and Databricks, is increasingly important.
- Programming and Scripting: Advanced coding skills in languages relevant to data engineering, such as Python, Scala, or Java, are non-negotiable.
- Data Governance and Compliance: Understanding data governance frameworks and compliance requirements is critical, especially in highly regulated industries.
- Leadership and Communication: Beyond technical skills, the ability to lead projects, communicate effectively with both technical and non-technical team members, and mentor junior engineers is what differentiates a senior engineer.
Learning Pathways#
Becoming a senior data engineer requires continuous learning and real-world experience. Here are a few steps to guide your journey:
- Educational Foundation: Start with a strong foundation in computer science or a related field. This can be through formal education or self-study courses.
- Gain Practical Experience: Apply your skills in real-world projects. This could be in a professional setting, contributions to open-source projects, or personal projects.
- Specialize and Certify: Consider specializing in areas particularly relevant to your interests or industry needs. Obtaining certifications in specific technologies or platforms can also bolster your credentials.
- Develop Soft Skills: Work on your communication, project management, and leadership skills. These are as critical as your technical abilities.
- Seek Feedback and Mentorship: Learn from the experiences of others. Seek out mentors who can provide guidance and feedback on your progress.
Video 1#
| Live Stream -> How to become a Senior Data Engineer - Part 1 |------------------| | In this part one I talked about Data Modeling, Big Data, ETL, Data Warehousing & Data Lakes as well as Cloud computing | Watch on YouTube|
Video 2#
| Live Stream -> How to become a Senior Data Engineer - Part 2 |------------------| | In part two I talked about real time data processing, programming & scripting, data governance, compliance and data security | Watch on YouTube|
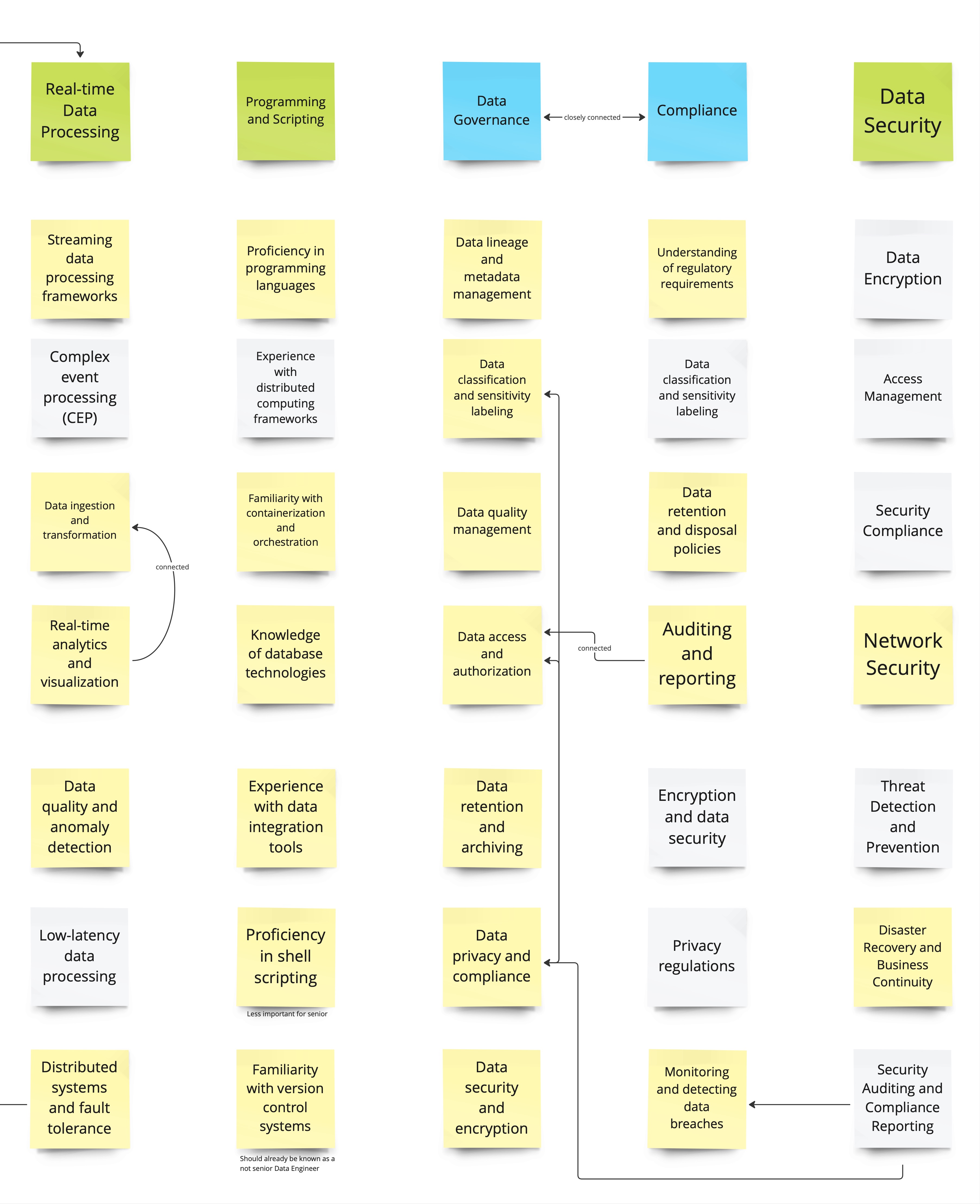
Video 3#
| Live Stream -> How to become a Senior Data Engineer - Part 3 |------------------| | In part 3 I focused on everything regarding Leadership and Communication: team management, project management, collaboration, problem solving, strategic thinking, communication and leadership | Watch on YouTube|
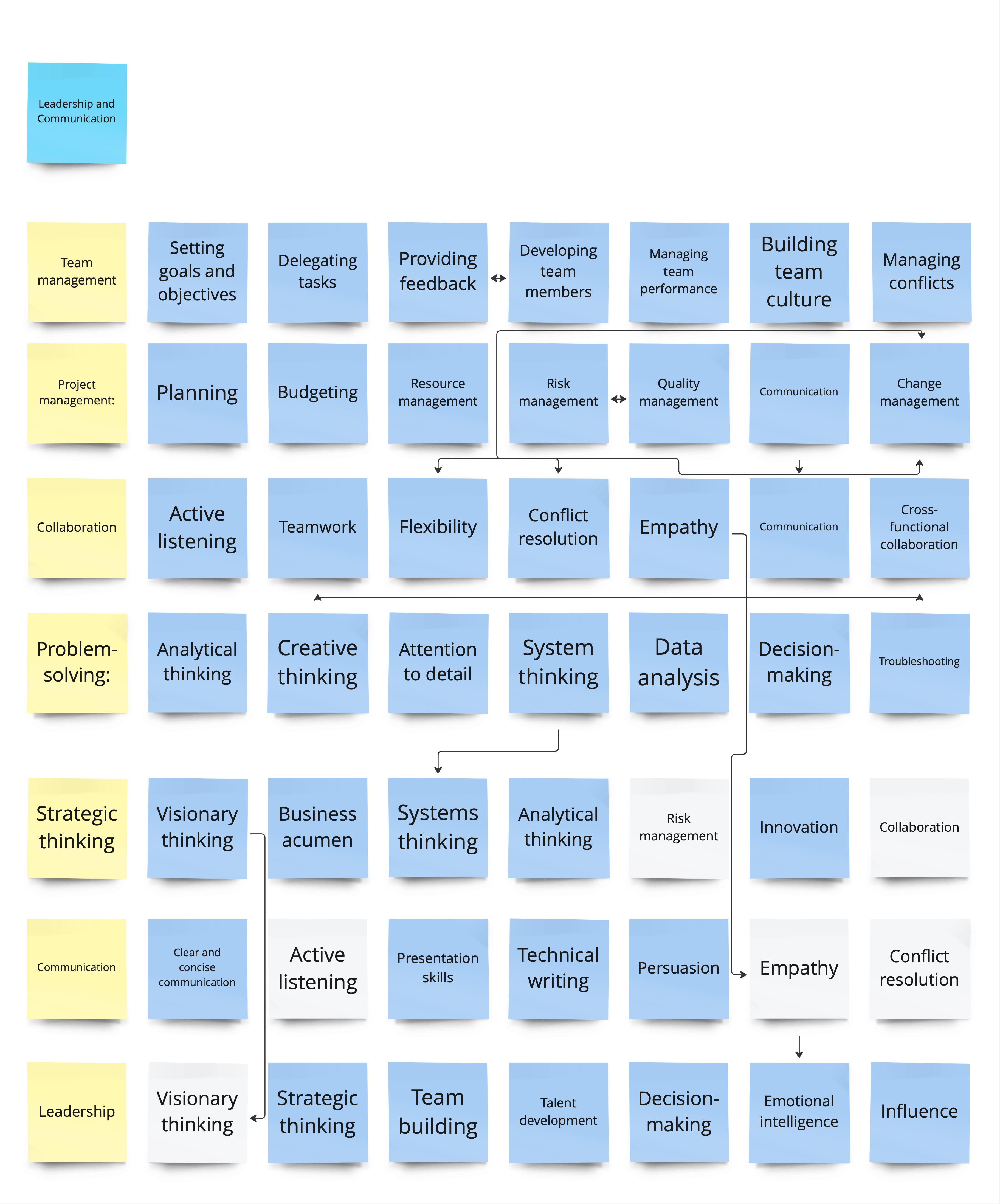
Final Thoughts#
The path to becoming a senior data engineer is both challenging and rewarding. It requires a blend of technical prowess, continuous learning, and the development of soft skills that enable you to lead and innovate. Whether you're just starting out or looking to advance your career, focusing on the key areas outlined above will set you on the right path.